写在前面
记得在的文章中提到,Glove和Word2vec,对于每一个单词都有唯一的一个embedding表示,而对于多义词显然这种做法不符合直觉,而单词的意思又和上下文相关。ELMo (Embeddings from Language Models)的做法是只预训练language model(LM),而word embedding是通过输入的句子实时输出的, 这样单词的意思就是上下文相关的了,这样就很大程度上缓解了歧义的发生,且ELMo输出多个层的embedding表示,试验中已经发现每层LM输出的信息对于不同的任务效果不同, 因此对每个token用不同层的embedding表示会提升效果。
结构
使用双向的LM,计算N个tokens($t_1,t_2,…,t_N$),LM通过前k-1个token计算第k个token出现的概率:
后向计算:
双向biLM训练过程中的目标就是最大化:
ELMo对于每个token $t_k$,通过一个L层的biLMdedao 2L+1个表示:
其中,$x_k^{LM}$是对字符直接进行CNN编码,即上式的$h_{k,0}^{LM}$。而$h_{k,j}^{LM} = \{ \overrightarrow{h}_{k,j}^{LM},\overleftarrow{h}_{k,j}^{LM} \}$是biLSTM层的输出结果。
在应用中,最简单的压缩方法是取最后一层的输出做为token的表示:$E(R_k) = h_{k,L}^{LM}$。更通用的做法是通过一些参数来联合所有层的信息:
其中,
- $s_j$是一个softmax出来的结果
- $\gamma$是任务相关的scale参数
Pre-trained的language model是用了两层的biLM, 对token进行上下文无关的编码是通过CNN对字符进行编码, 然后将三层的输出scale到1024维,最后对每个token输出3个1024维的向量表示。
biLM
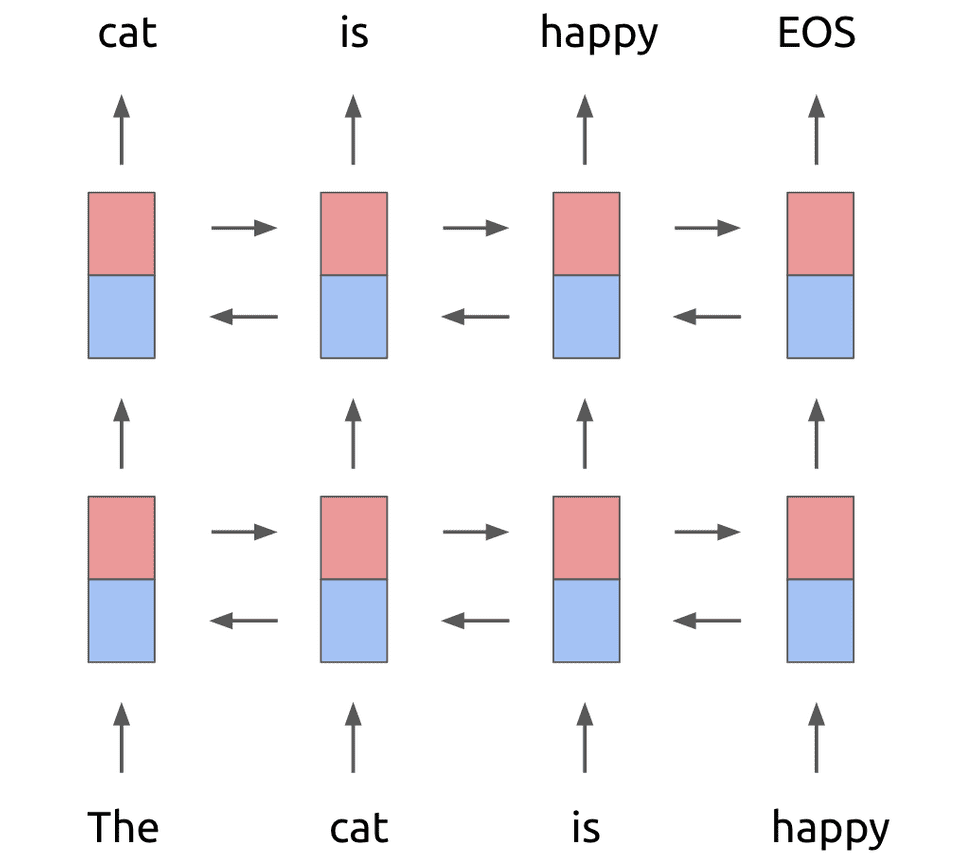
上面这个两层的神经网络,在第一层和第二层中间添加残差块连接如下:
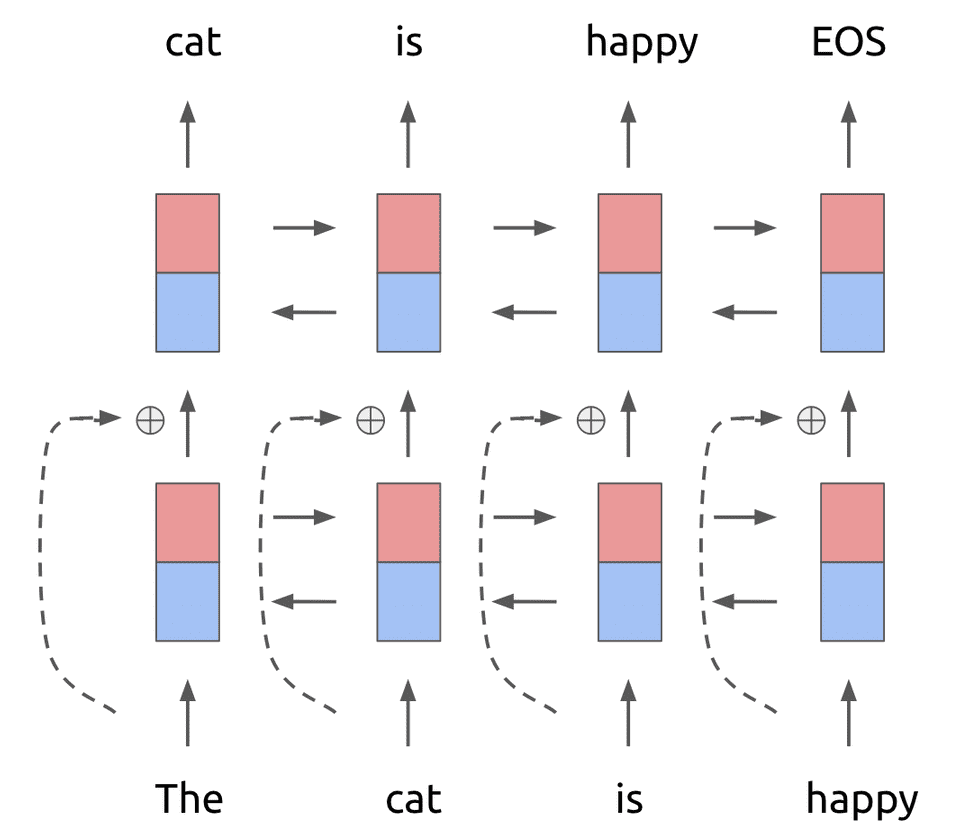
对于传统的神经网络而言,每个token在第一个输入层会被转化为特定长度的词向量,主要是通过初始化一个embedding matrix,或者使用GloVe等预训练向量。但是ELMo并不是简单地look up an embedding,而是首先将每个token使用字符编码,主要是用过CNN+max pool+2-layer highway network 进行编码,之后再输入到LSTM层中。
字符编码
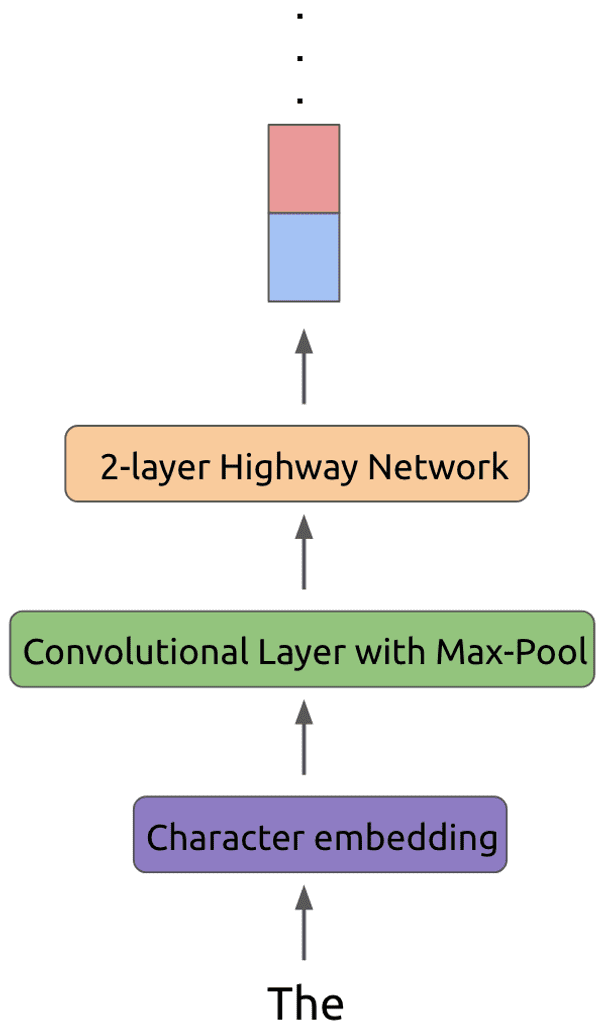
字符编码的好处是:
- 获得词编码中提取不到的信息
- 对oov单词形成一些有效的表征
CNN filters的好处是:能够提取n-gram特征
highway network的好处是:smoother information transfer through the input
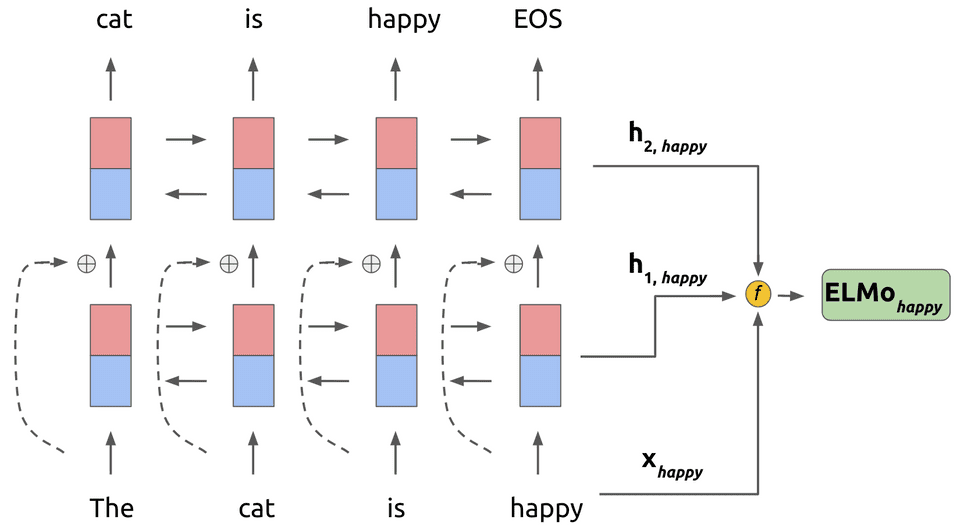
上面图片中,f函数最终对输入的word k(图中即happy)执行以下操作:
Highway Network
传统的神经网络
传统的神经网络对输入使用一个非线性变换$H$来得到输出output,公式如下:
x表示输入,$W_H$表示权重。
Highway Network
Highway network基于门机制引入了transform gate $T$ 和carry gate $C$ ,输出output是由tranform input和carry input组成:
为了简单,设置$C=1-T$,即:
其中,$x,y,H(x,W_H),T(x,W_T)$的维度是一样的,特别的:
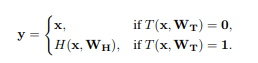
该层的雅可比变换为:
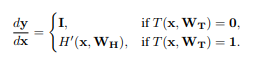
可以看到Highway Network其实就是对输入一部分进行处理(和传统神经网络相同),一部分直接通过。
因此,类似于传统神经网络plain layer计算第i个神经元输出:$y_i = H_i(x)$,highway network计算就是:
其中transform gate计算方法为:
$W_T、b_T$分别为权重矩阵和bias vector,$b_T$一般为负值(如-1,-3),使得网络初始的时候更偏向carry behavior。在实验中还发现将$b_T$设置成负值,即是网络层数很深, 用各种各样的方法初始化用不同的激活函数都可以让网络高效的学习。
缺点
虽然ELMo有用双向RNN来做encoding,但是这两个方向的RNN其实是分开训练的,只是在最后在loss层做了个简单相加。这样就导致对于每个方向上的单词来说,在被encoding的时候始终是看不到它另一侧的单词的。而显然句子中有的单词的语义会同时依赖于它左右两侧的某些词,仅仅从单方向做encoding是不能描述清楚的。所以,在BERT中,提出了使用一种新的任务来训练监督任务中的那种真正可以双向encoding的模型,这个任务称为Masked Language Model (Masked LM)。
代码
源码来自:https://github.com/allenai/allennlp
其他使用参考:Elmo词向量中文训练过程杂记
参考文献:
[1]. NAACL2018 一种新的embedding方法Deep contextualized word representations ELMo原理与用法
[2]. Deep Contextualized Word Representations with ELMo
[3]. https://arxiv.org/pdf/1802.05365.pdf
[4]. Highway network