写在前面
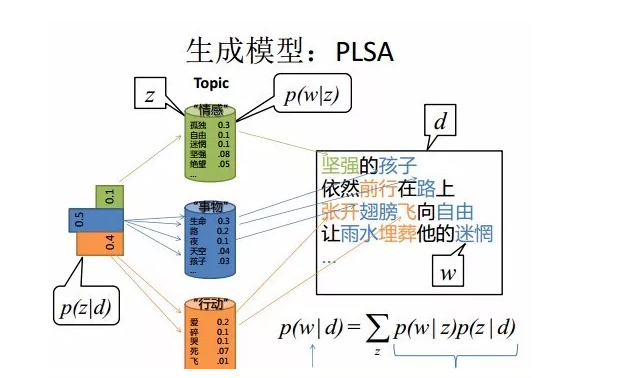
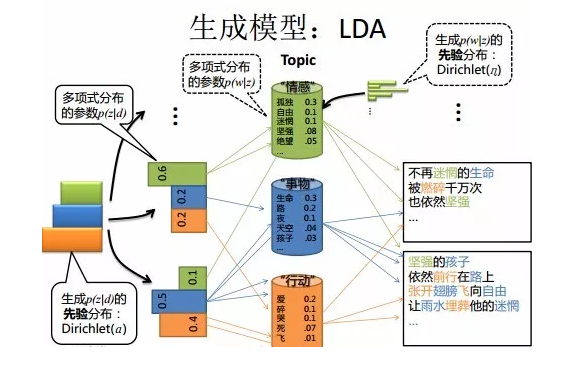
PLSA:多项分布+EM算法[2]
PLSA并没有考虑参数的先验知识,这时候出现了另一个改进的算法:
LDA:Dirichlet分布+Gibbs采样
LDA涉及到的先验知识有:二项分布、Gamma函数、Beta分布、多项分布、Dirichlet分布、马尔科夫链、MCMC、Gibbs Sampling、EM算法等。涉及概念众多,所以也是导致它晦涩难懂的主要原因。
伯努利分布
伯努利分布(the Bernoulli distribution,又名两点分布或者0-1分布),是一个离散型概率分布,记其成功概率为p(0≤p≤1),失败概率为q=1-p。
二项分布
单次抛硬币是伯努利分布,多次抛硬币是二项分布。二项分布中:
当n = 1时,二项分布就是伯努利分布。
多项分布
多项分布,是二项分布扩展到多维的情况. 多项分布是指单次试验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3…,k).概率密度函数为:
Gamma函数
Gamma函数的定义:
分部积分后,Gamma有如下性质:
Gamma可以看做是阶乘在实数集上的拓展,具有如下性质:
Beta分布
公式来源

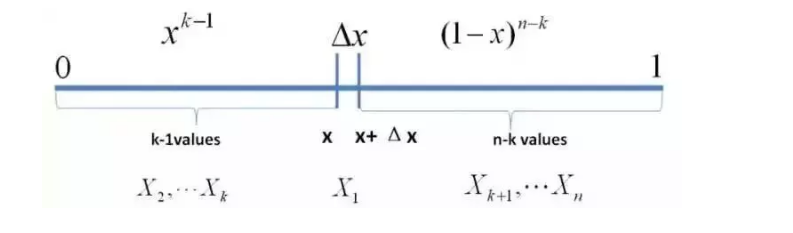
解决这个问题,可以尝试计算 落在区间$[x,x+\Delta x]$的概率。首先,把[0,1]区间分成三段$[0,x),[x,x+\Delta x],(x+\Delta x,1]$,然后考虑下简单的情形:即假设n个数中只有1个落在了区间$[x,x+\Delta x]$内,由于这个区间内的数X(k)是第k大的,所以[0,x)中应该有k−1个数,$(x+\Delta x,1]$这个区间中应该有n−k个数。(其实这个假设也可以认为计算是伯努利分布参数为$p=\frac{k}{n}$的概率,又因为p本身也是概率,所以是暗示了分布的分布) 如下图所示:
上述问题可以转换为下述事件E:
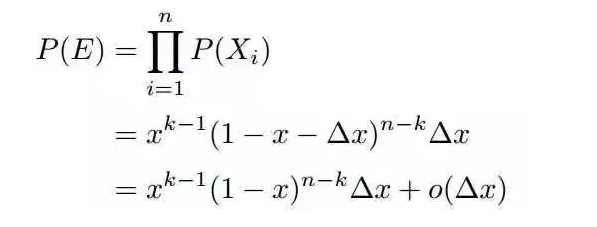
其中,$ o(\Delta x)$表示$\Delta x$的高阶无穷小。显然,由于不同的排列组合,即n个数中有一个落在$[x,x+\Delta x]$区间的有n种取法,余下n−1个数中有k−1个落在[0,x)的有C(n-1,k-1)种组合。所以和事件E等价的事件一共有nC(n-1,k-1)个。
只要落在$[x,x+\Delta x]$内的数字超过一个,则对应的事件的概率就是$o(\Delta x)$。所以的概率密度函数为:
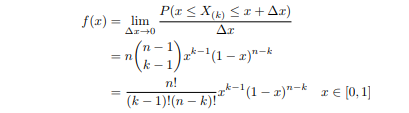
利用Gamma函数,我们可以将f(x)表示成如下形式:
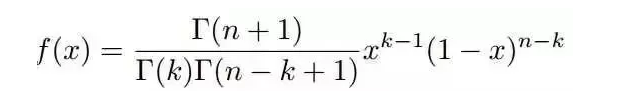
在上式中,我们用$\alpha=k,\beta=n-k+1$替换,可以得到beta分布的概率密度函数。
定义
对于参数$\alpha>0,\beta>0$,取值范围在[0,1]的随机变量x的概率密度函数为:
其中,$β∈[0,1],\frac{1}{B(α,β)} = \frac{Γ(α+β)}{Γ(α)Γ(β)} $。$\alpha、\beta$为伪计数,即我们的先验知识告诉我们这两种事件发生的次数。
Dirichlet分布
Dirichlet的概率密度函数为:
其中,
有些地方将$p_i,\alpha_i$写成向量形式,即$\vec{p},\vec{\alpha}$。另外,Dirichlet分布还可以表示为:
$\Delta(\vec{\alpha})$是归一化因子:
共轭先验分布
在贝叶斯概率理论中,如果后验概率$p(\theta|x)$和先验概率$p(\theta)$满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数$ p(\theta|x) $的共轭先验分布。
Beta分布是二项式分布的共轭先验分布,而狄利克雷(Dirichlet)分布是多项式分布的共轭先验分布。
贝叶斯学派的最基本的观点是,任何一个未知量θ,都可以看作一个随机变量,应用一个概率分布去描述θ的未知状况。这个概率分布是在抽样前就有关于θ的先验信息的概率陈述,这个概率分布被称为先验分布。
Beta-Binomial

按照贝叶斯推理的逻辑,把以上过程整理如下:
1、p是我们要猜测的参数,我们推导出p的分布为$f(p)=Beta(p|k,n-k+1)$,称为p的先验分布
2、根据$Y_i$中有$m_1$个比p小,有$m_2$个比p大,$Y_i$相当是做了m次伯努利实验,所以$m_1、m_2$服从二项分布$B(m,p)$
3、在给定了来自数据提供$(m_1,m_2)$知识后,p的后验分布变为:
贝叶斯估计的基本过程是:
先验分布 + 数据的知识 = 后验分布
以上贝叶斯分析过程的简单直观的表示就是:
$Beta(p|k,n-k+1) + BinomCount(m_1,m_2) = Beta(p|k+m1,n-k+1+m2)$
更一般的,对于非负实数alpha和beta,我们有如下关系:
$Beta(p|\alpha,\beta) + BinomCount(m_1,m_2) = Beta(p|\alpha+m_1,\beta+m_2)$
针对于这种观测到的数据符合二项分布,参数的先验分布和后验分布都是Beta分布的情况,就是Beta-Binomial共轭。换言之,Beta分布是二项式分布的共轭先验概率分布。二项分布和Beta分布是共轭分布意味着,如果我们为二项分布的参数p选取的先验分布是Beta分布,那么以p为参数的二项分布用贝叶斯估计得到的后验分布仍然服从Beta分布。
公式证明

分布的分布
举个栗子:
Beta分布可以看做是分布之上的分布。我们还是以抛硬币为例。不过,我们并不假设硬币是均匀的(也就是说:并不假设每次抛硬币,正面朝上的概率为0.5),所以抛硬币的正面朝上的概率p是未知的(只知道p∈[0,1])。如果进行一次二项分布试验,在这次二项分布试验中,抛硬币10000次,其中正面朝上7000次,反面朝上3000次,我们可以得到,正负面朝上的概率分别为{p,1-p}={0.7,0.3}。但是我们并不确信这个结果是正确的。我们想要做10000次二项分布试验,在每次二项分布试验中,均抛硬币10000次(说不定在其他二项分布实验中,得到的正负面朝上的概率是{0.2,0.8}或者{0.6,0.4},这些情况都有可能),那么,我们想要知道,在这样的多次重复二项分布实验中,抛硬币最后得到正负面朝上概率为{0.7,0.3}这样概率为多少?这就是在求抛硬币的概率分布之上的分布。这样的分布就叫做Beta分布。
正如二项分布可以看做多次进行伯努利试验所得到的分布一样,Beta分布也可以看做是多次进行二项分布的试验所得到的分布,是分布之上的分布。
为什么需要共轭分布
为什么LDA要假设共轭分布呢?当某个似然概率异常复杂时,后验概率计算会叫人难以理解,使用共轭先验可以简化问题。从Beta-Binomial可以看出,选择与似然函数共轭的先验,得到的后验函数只是参数调整后的先验函数。
先验概率取为共轭先验的好处就在于:每当有新的观测数据,就把上次的后验概率作为先验概率,乘以新数据的likelihood,然后就得到新的后验概率,而不必用先验概率乘以所有数据的likelihood得到后验概率。
Beta/Dirichlet分布的一个性质
如果$p\text{~}Beta(t|\alpha,\beta)$,则:
上面右边的积分对应到概率分布$Beta(t|\alpha+1,\beta)$,对于这个分布有:
把上式带回E(p)的计算式:
这说明,对于对于Beta分布的随机变量,其均值可以用$\frac{\alpha}{\alpha+\beta}$来估计。Dirichlet分布也有类似的结论,如果p服从于$Dir(\vec{p}|\vec{\alpha})$,同样可以证明:
对于后验分布,假设$\vec{p}$的后验分布为$Dir(\vec{p}|\vec{n}+\vec{\alpha})$,即有:
也就是说对于每一个$p_i$ 用下式做参数估计:
这个重要性质会在Gibbs Sampling中推导用到。
LDA主要思想
LDA生成文档的过程如下:
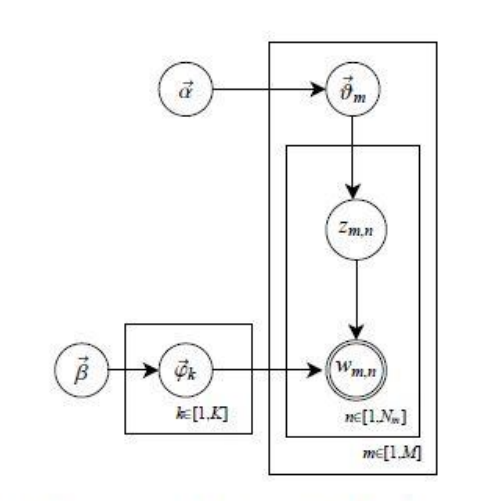
同种,K为主题个数,M为文档总数,$N_m$是第m个文档的单词总数,$\vec{\beta}$是每个Topic下词的多项分布的Dirichlet先验参数(一个$\beta$生成一个词的多项分布的参数),$\vec{\alpha}$是每个文档下Topic的多项分布的Dirichlet先验参数(一个$\alpha$生成一个主题多项分布的参数)。$z_{m,n}$是第m个文档中第n个词的主题,$w_{m,n}$是m个文档的第n个词。$\vec{\theta_m}$和$\vec{\phi_k}$是隐变量,分别表示第m个文档下的Topic分布和第k个Topic下的词分布。

简单理解为两个物理过程:
我们可以写出最后所有变量的联合分布:
简单点写,最后的目标是求:
根据Dirichlet公式,分别计算$p(\vec{z}|\vec{\alpha})$和$p(\vec{w}|\vec{z},\vec{\beta})$如下:
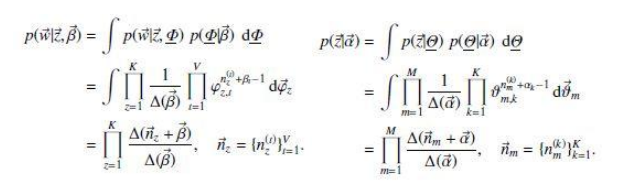
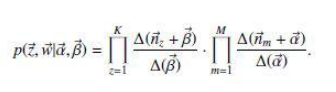
$\vec{n}_z$表示term t被观察到分配 topic z 的次数, $\vec{n}_m$表示topic k分配给文档m中的 word 的次数。
这个联合概率公式是非常难计算的, 所以需要采用Gibbs Sampling算法进行采样计算这个联合概率公式。 因为$w$是已经观测到的样本, $z$是初始计算时随机分配的topic, 所以最终的目的是要$z$实现收敛, 这样在LDA的plate model中的每篇文档对应的topic 分布 和每个topic下对应的term的分布就自然也是收敛的了。
Gibbs Sampling
由于LDA中含有隐变量,参数估计方法一般有精确计算(exact inference)和近似计算(approximate inference)。精确计算是很困难的,所以一般采用近似计算。
对于给定的概率分布$p(X)$,我们希望构造一个从任何初始状态$x_0$出发,都能沿着马氏链转移直到收敛到平稳分布,这个分布就是我们想要得到的分布。基于这个思想,Metropolis在1953年首次提出基于马氏链的蒙特卡洛方法,并启发了一系列MCMC算法。
Gibbs Sampling算法是MCMC的一个特例,如果某个概率$P(X)$不易求得,那么可以交替地固定某一维度$x_i$,然后通过其他维度$x_{¬i}$(去除$x_i$的其他所有值)的值来抽样近似求解,也就是说,Gibbs采样就是用条件分布的采样来替代全概率分布的采样。
假设有一个概率分布$p(x,y)$,考察x坐标相同的两个点A$(x_1,y_1)$和B$(x_1,y_2)$,我们发现:
结果得到
Gibbs采样的来源参考[1],二维采样过程:

LDA与Gibbs Sampling

初始时随机给文本中的每个单词分配主题$z^{(0)}$,然后统计每个主题$z$下出现$term \ t$的数量以及每个文档$m$下出现主题$z$中给的词的数量,每一轮计算$P(z_i|z_{¬i},d,w)$,即排除当前词的主题分配,根据其他所有词的主题分配估计当前词分配的各个主题的概率。当得到当前词属于所有主题$z$的概率分布后,根据这个概率分布为该词sample一个新的主题$z^{(1)}$。
用同样的方法不断更新下一个词的主题,直到发现每个文档下Topic分布$\theta_m$和每个Topic下词的分布$\phi_k$收敛,算法停止,输出待估计的参数$\theta_m$和$\phi_k$,最终每个单词的主题$z_{m,n}$也同时得出。实际应用中会设置最大迭代次数。
这里面涉及Gibbs sampling更新规则,对于第m篇文档中的第n个词,我们用$¬_i$表示去除下标为$i$的词。那么按照Gibbs Sampling算法的眼球,我们要求得任一个坐标轴i对于的条件分布$P(z_i=k|\vec{z}_{¬i},\vec{w})$。假设已经观察到的词$w_i=t$,则由贝叶斯公式:
由于$w_i=k,w_i=t$只涉及到第m篇文档和第k个主题,由于语料在每轮计算排除掉当前词即第i个词对于的$(z_i,w_i)$,并不改变Dirichlet-Multinomial共轭结构,因此由上一个LDA的结果,排除掉当前词,即:
计算结果套用了第九点说的关于重要性质:

注意以上公式和原来LDA公式的差别!
当Gibbs Samling收敛后,要根据最后文档的所有单词的主题分配,计算$\vec{\theta}_m$和$\vec{\phi}_k$,每个文档Topic后验分布和Topic下的词分布如下:
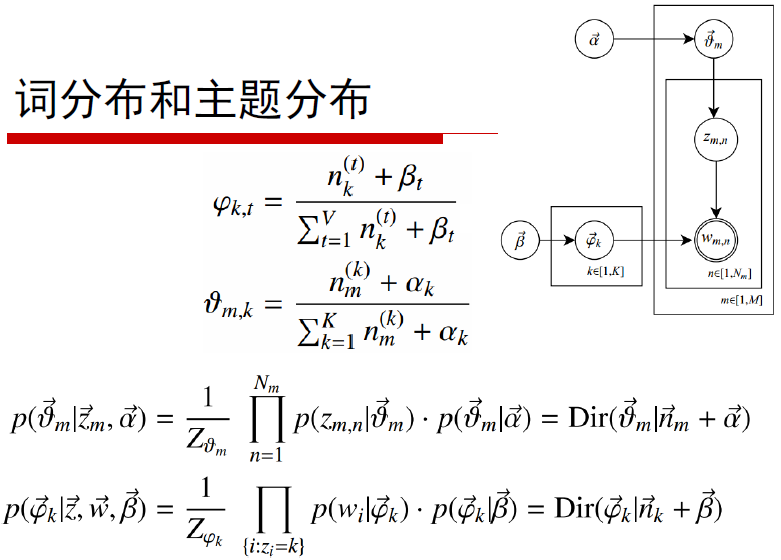
图中是由下面两行公式根据Dirichlet分布的期望计算公式,最终得到上面两行计算结果。

完整过程
注意 一个文档可以有N个主题,一个主题可以有M个单词,但是一个单词只有一个主题。
训练过程

测试过程

训练过程是为了得到每个词的主题,即(z,w)样本对。
推断阶段,尤其是给定新文档的推断,可以假定词分布已经确定,只更新新文档的主题分布即可。
主题个数评价指标
根据困惑度的下降速度,查看最佳拐点
根据coherence分数,查看最佳拐点 代码参考
计算KL散度
计算各个主题的相似度
最常用也是最靠谱的,还是人工确定主题个数
缺点
一、短文本上效果不好,原因是document-level word co-occurrences 很稀疏。解决这个问题的方式:
- 是如word2vec一样,利用local context-level word co-occurrences。 也就是说,把每个词当成一个文档以及把它周围出现过的词当做这个文档的内容。这样的话就不会受文档长度的限制了。
- 短文本语义更集中明确,LDA是适合处理的,也可以做一些文本扩展的工作,有query log的话,1). query session,2). clickstream。无query log的话,1). 短文本当做query,通过搜索引擎(或语料库)获取Top相关性网页,2). 用语料库中短文本周边词集,3). 知识库中近义词,上下位词等。
- Twitterlda:Twitter-LDA的大致思想其实很简单,他从每个用户的角度上考虑,每个用户有个topic分布矩阵,然后每一个tweet的生成是根据这个矩阵选出来的topic再去选单词。
二、没有较好地结合相关语义强化机制,主题语义连贯性较差,很难为人所理解。
三、参数推断过程中没有显式地考虑上下文信息,使得对于主题的分配过程难以收敛到一个较好的状态。
四、传统的主题模型仍然是一种浅层的表示结构,存在特征表达能力不强等缺点。
参考文献:
[1]. LDA数学八卦
[2]. PLSA及EM算法-yangliuy.pdf
[3]. LDA及Gibbs-Sampling-yangliuy.pdf
[4]. 各个分布
[5]. 共轭分布
[6]. 神经主题模型
[7].