相关知识
目前主流的两种模型都存在一些显著的不足。对于一些global matrix factorization方法(如LSA),在词类比任务的表现不好,表明这种方法得到的是向量空间的次优解;对于一些local context window方法(如skip-gram)可能在词类比任务上表现比较好,但这种方法没有很好得利用语料库的统计信息因为它们只在局部上下文中进行训练。
GloVe模型就是将这两中特征合并到一起的,包括:全局特征的矩阵分解方法(global matrix factorizations)和局部上下文窗口(local context window),为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。
共现矩阵
$X$ :共现矩阵
$X_{ij}$:单词j在单词i的上下文出现的次数
$X_i = \sum _k X_{ik}$:表示单词j出现在单词i上下文的次数
$P_{ij} = P(j|i) = \frac{X_{ij}}{X_i}$:表示单词j出现在单词i上下文的概率
考虑两个在某些方面比较类似的词:i代表ice,j代表steam。这两个词的关系可以通过研究它们与某个词k的共现概率之比来得到。
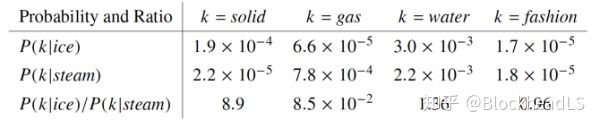
(1)如果k和i相关,k和j不相关, $\frac{P_{ik}}{P_{jk}}$很大;
(2)如果k和i不相关,k和j相关, $\frac{P_{ik}}{P_{jk}}$很小;
(3)如果k和i、j都相关,或者都不相关, $\frac{P_{ik}}{P_{jk}}$接近1。
GloVe的目标就是获取每一个word的词向量表示v,而这些词向量所呈现的规律和$Ratio = \frac{P_{ik}}{P_{jk}}$具有一致性,即词向量中包含了共现矩阵中的信息。
目标函数
1、构造一个向量函数,使得:
2、$w$是单词词向量,$\tilde{w}$是上下文词向量。为了考察$w_i$和$w_j$之间的关系,自然联想到的是两个向量之间的差,所以F函数的形式可以是:
3、上面的公式中,$\frac{P_{ik}}{P_{jk}}$是一个标量,而F是计算两个向量。向量和标量的关系自然联想到使用内积,因此F函数的形式进一步确定为:
4、由于左边为差,右边为商,将F函数取作$exp$将差和商关联起来:
那么现在只需要文中$exp(w_i^T\tilde{w_k}) = P_{ik}$,即:
5、这里要考虑一个最重要的约束:对称性问题
单词词向量$w$和上下文词向量$\tilde{w}$是相等的:When $X$ is symmetric,$W$ and $\tilde{W}$ are
equivalent and differ only as a result of their random initializations; the two sets of vectors should perform equivalently.
此时,交换左边的顺序:$w^T_i\tilde{w_k} = w^T_k \tilde{w_i}$。但右边交换顺序$log X_{ik}-logX_i ≠log X_{ki} - log X_k$。为了解决对称性问题,引入了两个偏置项:
其中$b_i$包含了$log X_i$,为了保持对称性,又加入了$b_k$。
6、在实验中,左右两边要求结果接近,从而损失函数为:
V表示单词表的大小。
7、根据经验,如果两个词出现的次数越多,那么在损失函数中的影响就越大。因此根据其共同出现的次数,对每一项加权:
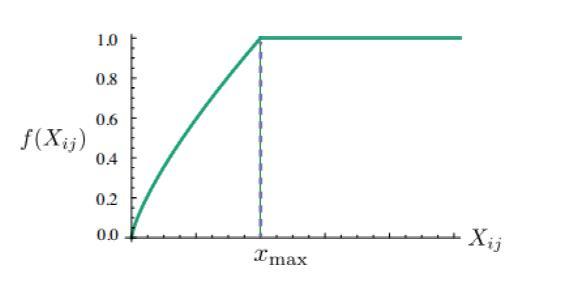
令$f(X_{ij})$为权重,则其应该满足三个条件:
$f(0)=0$,这样可以保证当$X_{ij}→0$时$lim_{x→0}f(x)log^2x$是有限值
$f(x)$应该是单调不减函数,这样不会导致共现次数低的值被赋予更多权重
$f(x)$在x值很大时应该相对比较小,这样不会导致共现次数很大的值被赋予过大权重
所以最终作者确定$f(x)$的表达式为:
当$\alpha=3/4$时,$f(x)$的图像为:
代码
实现代码参考:Glove实现
论文实现一些说明:
语料库中的词汇都符号化和并变为小写,建立一个含有400,000个常用词的词汇表。
利用上下文窗口来计数得到共现矩阵X。在利用上下文窗口时需要设定窗口的大小(论文采用了上下文各10个单词的窗口长度)和是否需要区分上文和下文等。
乘以一个随距离d递减的权重项,即与单词i距离为d的单词在计数时要乘上权重1/d,表示距离越远的词可能相关性越小。
- 采用AdaGrad的方法迭代50次(非监督学习,没有用神经网络)
- 作者从神经网络的训练中得到的灵感:对于某些神经网络,训练多个网络并把这些网络结合起来有助于减少过拟合和噪声并且能改善性能。受此启发,作者将W+˜W作为最终词向量,并且能够使得这些词向量在某些任务上的表现变好。
缺点
- 模型中最大的问题在于参数$b_i,b_j$也是可训练的参数
也就是说,对于glove训练处的词向量加上任意一个常数向量后,它还是这个损失函数的解!这意味着,当加上一个非常大的常数向量之后,它们仍然是解,但是这个解的词向量没有意义,因为任意两个词的cos接近为1。
- 和word2vec一样没有考虑一词多义
词向量的评价方法
- Word analogies, Word similarity等内部评估
- Named entity recognition、文本分类等外部评估
参考文献:
[1]. 通俗易懂Glove算法
[2]. Glove这个老古董
[3].