写在前面
很多文本处理的问题都可以变成QA问题:
机器翻译machine translation: (What is the translation into French?)
命名实体识别named entity recognition (NER) :(What are the named entity tags in this sentence?)
词性识别part-of-speech tagging (POS) :(What are the part-of-speech tags?)
文本分类classification problems like sentiment analysis: (What is the sentiment?)
指代问题coreference resolution: (Who does ”their” refer to?)
这篇主要介绍QA问答系统中的动态记忆网络模型(Dynamic Memory Network),它是由4部分构成的,包括输入模块、问题模块、情景记忆模块、输出模块。
数据集
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom 1
4 Daniel went back to the hallway.
5 Sandra moved to the garden.
6 Where is Daniel? hallway 4
7 John moved to the office.
8 Sandra journeyed to the bathroom.
9 Where is Daniel? hallway 4
10 Mary moved to the hallway.
11 Daniel travelled to the office.
12 Where is Daniel? office 11
13 John went back to the garden.
14 John moved to the bedroom.
15 Where is Sandra? bathroom 8
1 Sandra travelled to the office.
2 Sandra went to the bathroom.
3 Where is Sandra? bathroom 2
四个模块
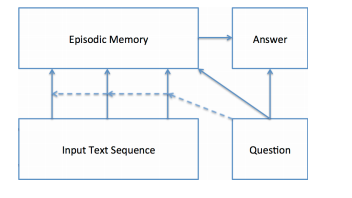
输入模块
对输入的句子进行GRU编码,将结果给到情景记忆模块。
如果输入为多个句子的话,那就在每个句子记录下结束时刻的位置,并在GRU编码后输出该位置对应的$ c_t$作为句子的向量表达:
1 | encoded_facts = [] |
问题模块
对输入的问题进行GRU编码,将结果给到情景记忆模块和回答模块。
同输入模块,将GRU编码后的结束位置的$q_t$作为句子的向量表达:
1 | encoded_questions = [] |
情景记忆模块
情景记忆模块输入为$h_t$和$q_t$,模块会生成一个记忆memory,初始时$m = q_t$,然后根据每一次的迭代更新$m^i = GRU(e,m^{i-1})$
注意力机制
保留比例门g充当着attention的作用 。特征函数z(c,m,q)提取了9个特征:
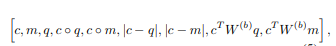
将特征函数输入到两层前向网络(分别用tanh和sigmoid激活):
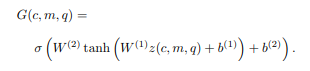
记忆更新机制
e先随机初始化,在每个句块的遍历时,e会结合句子和旧e去生成新的e的信息:
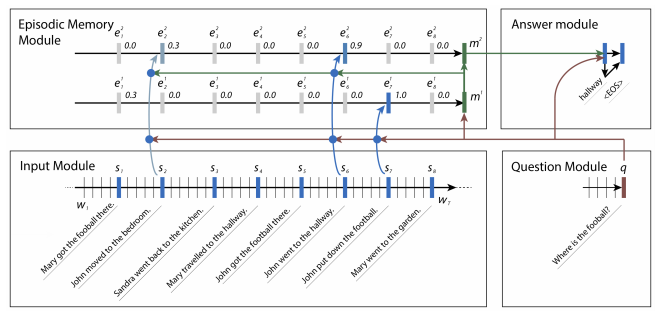
Need for Multiple Episodes: The iterative nature of this
module allows it to attend to different inputs during each
pass. It also allows for a type of transitive inference, since
the first pass may uncover the need to retrieve additional
facts. For instance, in the example in Figure, we are asked
Where is the football? In the first iteration, the model ought
attend to sentence 7 (John put down the football.), as the
question asks about the football. Only once the model sees
that John is relevant can it reason that the second iteration
should retrieve where John was. Similarly, a second pass
may help for sentiment analysis as we show in the experiments section below.
1 | memory = encoded_questions |
回答模块
回答模块结合memory和question,来生成对问题的答案。也是通过GRU来生成答案的。
有点类似解码器吧。最后注意,这里必须加上一个seqbegin作为回答起始的标志。
1 | answer_hidden = memory |
其他
代码参考:https://github.com/plmsmile/NLP-Demos/tree/master/question-answer-DMN
不过最后没怎么用到spt(support_sentence_id),如果可以换种方式加进去训练应该会有其他效果。
1 | def pad_batch_data(batch_data): |
参考链接: