什么是依存句法
依存句法分析( Dependency Parsing, DP) 或者依存关系分析,是通过分析语言单位内成分之间的依存关系揭示其句法结构。
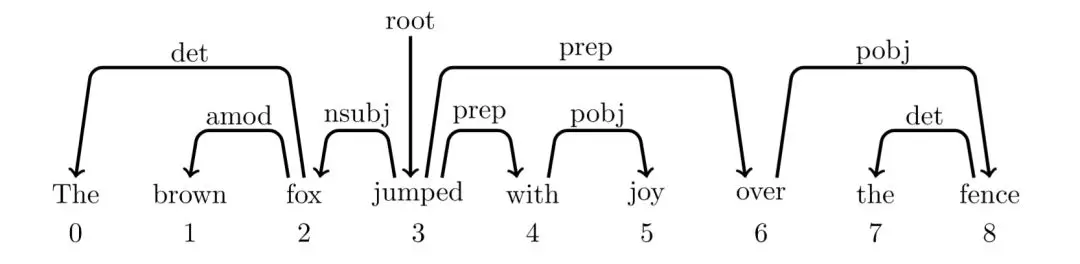
依存语法的结构没有非终结点,词与词之间直接发生依存关系,构成一个依存对。其中两个词之间的弧表示这两个词有依存关系,弧上的标签为二者的关系,弧的始发点为父亲节点,箭头指向为孩子节点。比如The 和 fox 是冠词+名词(det)的名词短语。
依存句法通常分为:基于图的依存句法和基于转移的依存句法。从理论上进行分析,基于图的依存分析与基于转移的依存分析有很多的不同。

本篇只介绍了基于转移的依存句法,对基于图的依存句法有兴趣的可以自己搜索。
五个条件
- 一个句子中只有一个成分是独立的,即核心成分;
- 句子的其他成分都从属于某一成分,即除了核心成分外的部分;
- 任何一个成分都不能依存于两个及以上的成分;
- 如果成分A直接从属成分B,而成分C在句子中位于A和B之间,那么,成分C或者从属于A,或者从属于B,或从属于A和B之间的某一成分(如果将从属关系用线条表示出来的话,那么这些线条不会发生交交错);
- 核心成分左右两边的其他成分相互不发生关系,相当于核心成分是一条界线,左右两边的部分不再发生支配关系
句法结构分析VS依存关系分析
句法分析分为句法结构分析(syntactic structure parsing)和依存关系分析(dependency parsing)。[2]
以获取整个句子的句法结构或者完全短语结构为目的的句法分析,被称为成分结构分析(constituent structure parsing)或者短语结构分析(phrase structure parsing)。这种短语语法用固定数量的rule分解句子为短语和单词、分解短语为更短的短语或单词。句法结构树示例如下图所示:
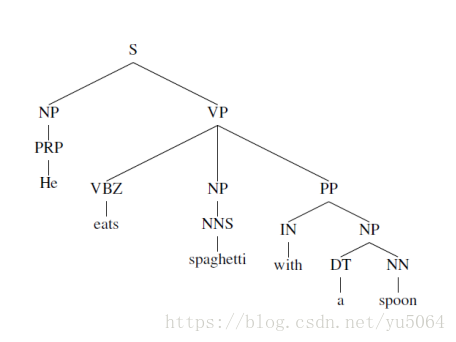
另外一种是以获取局部成分为目的的句法分析,被称为依存分析(dependency parsing)。用单词之间的依存关系来表达语法。如果一个单词修饰另一个单词,则称该单词依赖于另一个单词。
目前的句法分析已经从句法结构分析转向依存句法分析,一是因为通用数据集Treebank(Universal Dependencies treebanks)的发展,虽然该数据集的标注较为复杂,但是其标注结果可以用作多种任务(命名体识别或词性标注)且作为不同任务的评估数据,因而得到越来越多的应用,二是句法结构分析的语法集是由固定的语法集组成,较为固定和呆板;三是依存句法分析树标注简单且parser准确率高。
用途
可对相应树库(即Treebank)构建体系的正确性和完善性进行验证;
直接服务于各种上层应用,比如搜索引擎用户日志分析和关键词识别,比如信息抽取、自动问答、机器翻译等。
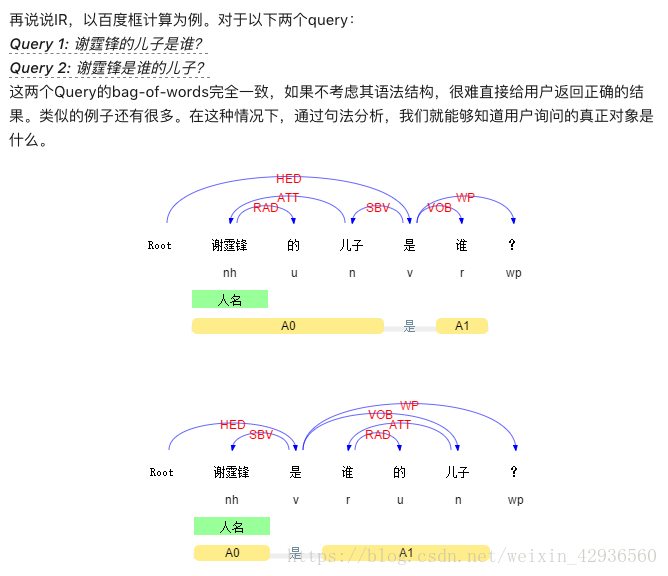
Treebank
树库(Treebank)是对句子进行分词、词性标注和句法结构关系标注的深加工语料库。根据所描述结构的不同 , 树库大体上可以分为两类 : 短语结构树库和依存结构树库 。 [4]
短语结构树库
短语结构树库一般采用句子的结构成分描述句子的结构。
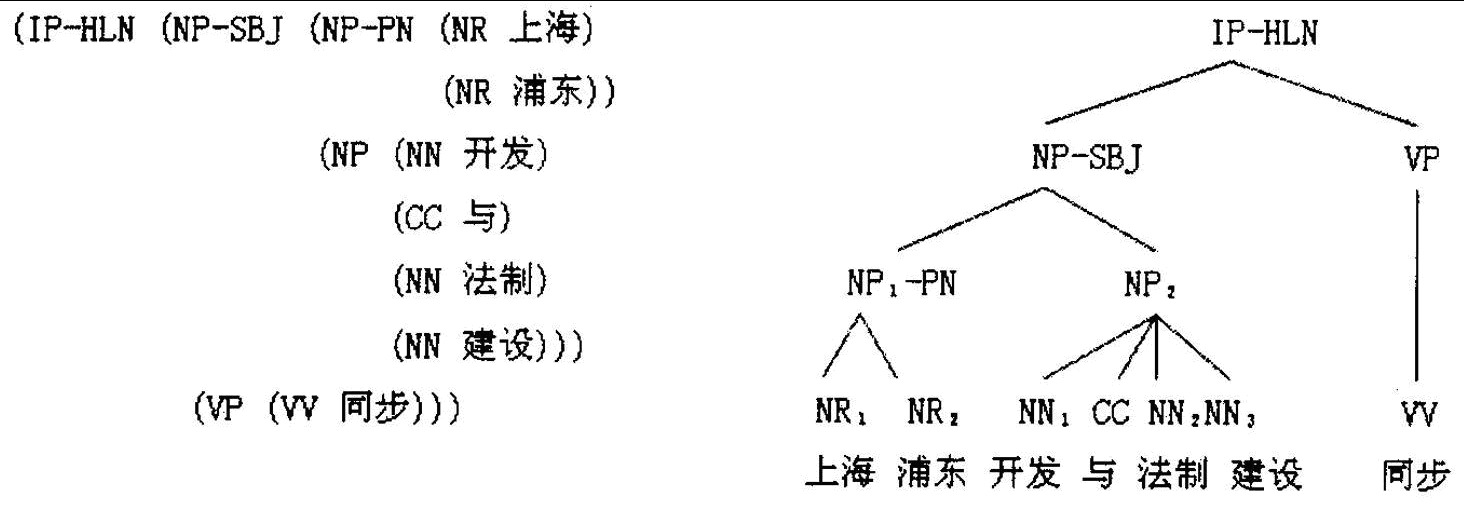
上图左边是可嵌套的语言规则与实例,右侧是它们的树状结构。
短语结构树库的目的是分析句子的产生过程。
依存结构树库
依存结构树库是根据句子的依存结构而建立的树库。依存结构描述的是句子中词与词之间直接的句法关系,相应的树结构也称为依存树。比如哈尔滨工业大学汉语依存树库中的一个例子:
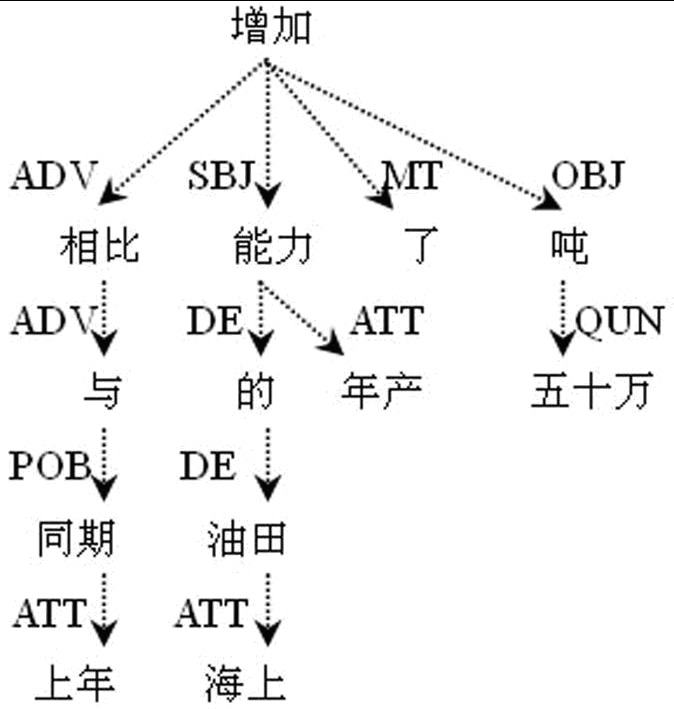
事实上,它可以投射(projective)为正常的线性句子“与上年同期相比,海上油田的年产能力增加了五十万吨”。又比如:
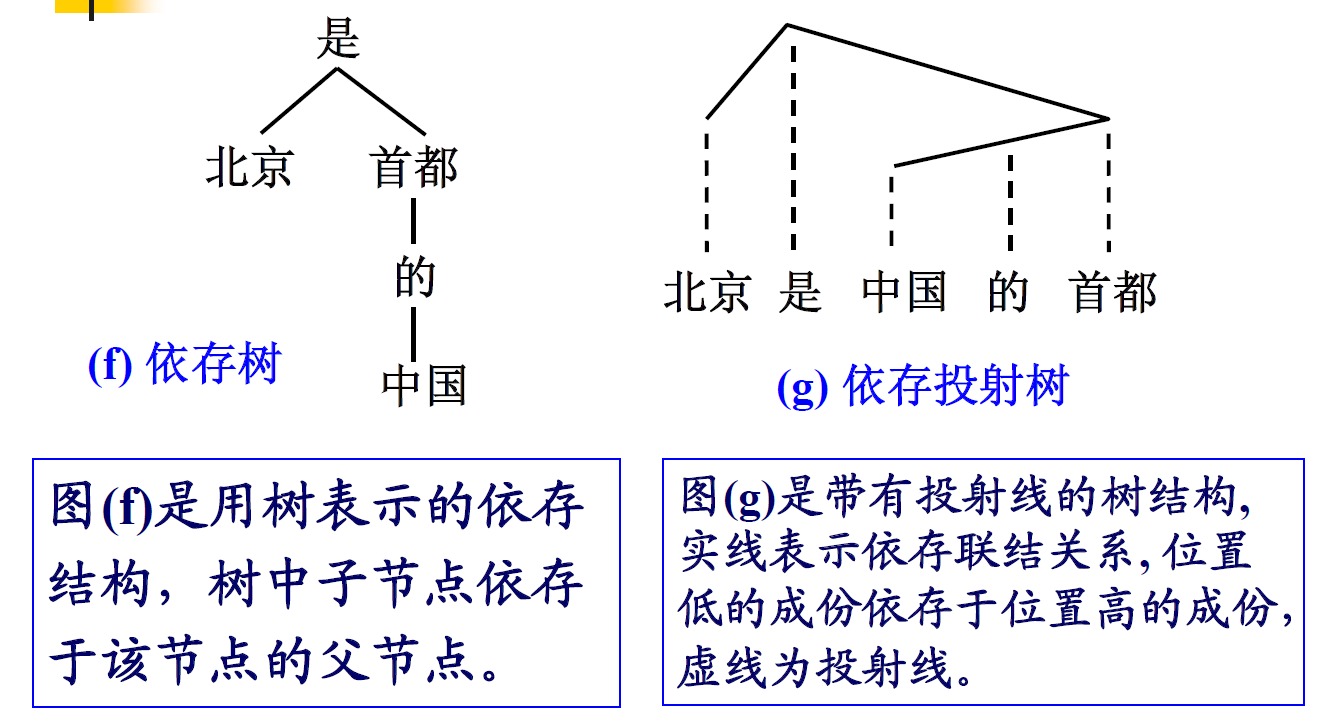
依存结构树库的目的并不是探讨句子如何产生这样宏伟的命题,而是研究已产生的句子内部的依存关系。
基于转移的依存句法
arc-standard
用在生成依存句法树上,则具体表示为从空状态开始,通过动作转移到下一个状态,一步一步生成依存句法树,最后的状态保存了一个完整的依存树。依存分析就是用来预测词与词之间的关系,现在转为预测动作序列。
在基于转移的框架中,我们采用arc-standard作为底层分析器,它定义了4种动作(栈顶的元素越小表示离栈顶越近):
- 移进(shift):队列首元素$q_0$出栈,压入栈成为$s_0$
- 左规约(arc_left):栈顶2个元素$s_1、s_0$规约,$s_1$下沉为$s_0$的左孩子节点,$l$为弧上关系
- 右规约(arc_left):栈顶2个元素$s_1、s_0$规约,$s_0$下沉为$s_1$的左孩子节点,$l$为弧上关系
- 根出栈(pop_root):根节点出栈,分析完毕。
举个栗子:
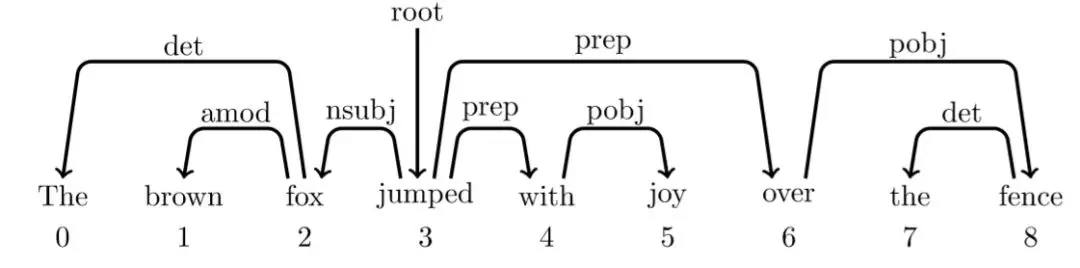
一整套依存分析的动作序列(金标,训练数据)就变为,每一行为一个configuration(包含了stack,buffer,依存弧集合的信息):
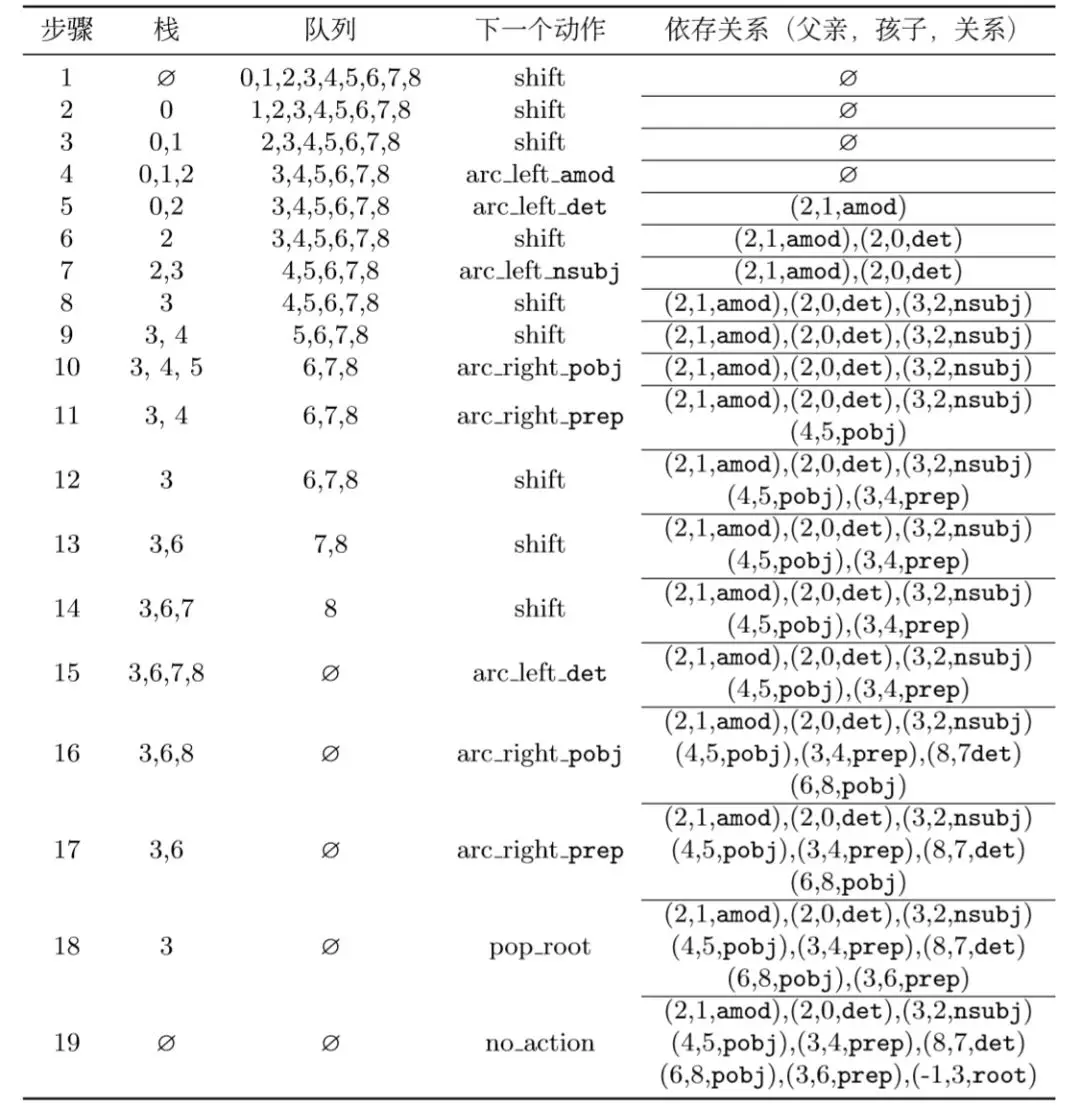
具体的流程请看[3]。
接下来就要进行特征抽取,一般而言,依存句法分析的可用特征:
1. Bilexical affinities(双词汇亲和)
2. Dependency distance(依存距离,一般倾向于距离近的)
3. Intervening material(标点符号两边的成分可能没有相互关系)
4. Valency of heads (词语配价,对于不同词性依附的词的数量或者依附方向)
传统的特征是栈和队列中的单词、词性或者依存标签等组合的特征,是一组很长的稀疏向量。 相比于使用大量的categorial (类别)特征,导致特征的sparse,使用神经网络可以使得特征更加dense,使用distributed representation of words减少特征的稀疏性。
数据结构
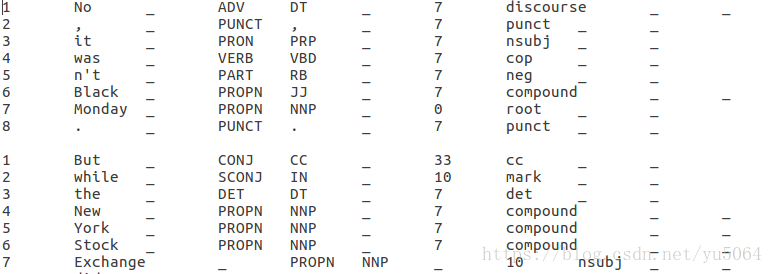
第一列是单词在句子中的序号,第二列是单词,第五列是POS tags,第七列是所依赖的序号,第八列是依赖关系也是arc labels。
神经网络
那么神经网络所做的事就是,输入单词word,词性POS tags,依赖关系arg labels,最终预测所依赖的序号head。
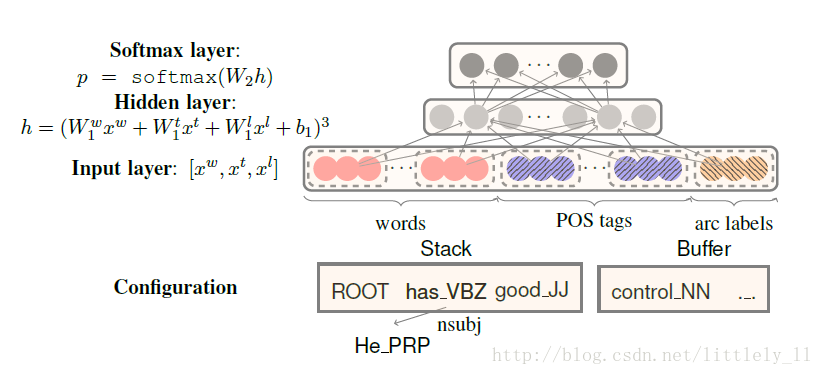
系统会分别选择18、18、12个元素作为$x^w,x^t,x^l$的值。
对于$x^w$,栈和缓冲区的前3个单词:$s_1,s_2,s_3,b_1,b_2,b_3$;堆栈顶部两个单词的第一个和第二个最左/最右边的子项,也就是依赖于该单词的单词,如果没有就是NULL。$lc1(s_i), rc1(s_i), lc2(s_i), rc2(s_i), i = 1, 2.$;堆栈顶部两个单词的最左边或最左边节点的最左边或最左边节点(孩子的孩子)$lc1(lc1(s_i)), rc1(rc1(s_i)), i = 1, 2$. 最后将这18个单词输入经过word embeddings映射为词向量。
对于$x^t$ 选择$x^w$中18个词的对应词性作为输入值。
对于$x^l$ 选择除了堆栈/缓冲区上的6个字之外的单词的相应弧标签。这些元素同样根据自己的embeddings映射为向量。
这样将所有的向量拼接起来就是input layer的输入。模型使用了 word embeddings,将one-hot编码转为词向量,不仅word,对应单词的词性和依存关系标签也被映射为向量,同样有自己的embeddings矩阵。
输入层是词向量,词性标注向量和弧标签向量的拼接层;隐含层使用了一个三次方的非线性函数;输出层就是一个softmax层,即$p=softmax(W_2h)$。
目标函数
交叉熵损失函数加上L2正则化:
其中,θ为${W^w_1,W^t_1,W^l_1,b_1,W_2,E_w,E_t,E_l}$的参数集,其中$E_w,E_t,E_l$是word、POS tags、arg labels的词向量。然后再用Adam来进行更新模型参数,最小化目标函数。
当然,也有其他网络结构,参考[1]。
代码
代码参考链接:https://github.com/akjindal53244/dependency_parsing_tf/blob/master/parser_model.py
工具:
stanfordcorenlp
pyltp
…
参考文献:
[1]. 详解基于转移的依存句法解析器
[2]. cs224n之句法分析
[3]. http://spark-public.s3.amazonaws.com/nlp/slides/Parsing-Dependency.pdf
[4]. 汉语树库