卷积神经网络
- 局部感知
- 共享权重(与RNN中的共享参数相区别)
padding
填充像素通常有两个选择,分别叫做Valid卷积和Same卷积。
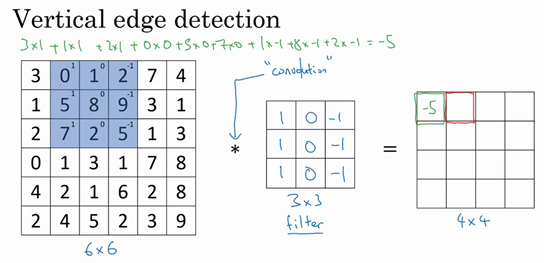
Valid卷积意味着不填充,这样的话,如果你有一个$n×n$的图像,用一个$f×f$的过滤器卷积,它将会给你一个$(n-f+1)×(n-f+1)$维的输出。这类似于我们在前面的视频中展示的例子,有一个6×6的图像,通过一个3×3的过滤器,得到一个4×4的输出。
另一个经常被用到的填充方法叫做Same卷积,那意味你填充后,你的输出大小和输入大小是一样的。根据这个公式$n-f+1$,当你填充$p$个像素点,$n$就变成了$n+2p$,最后公式变为$n+2p-f+1$。因此如果你有一个$n×n$的图像,用$p$个像素填充边缘,输出的大小就是这样的$(n+2p-f+1)×(n+2p-f+1)$。如果你想让$n+2p-f+1=n$的话,使得输出和输入大小相等,如果你用这个等式求解$p$,那么$p=(f-1)/2$。所以当$f$是一个奇数的时候,只要选择相应的填充尺寸,你就能确保得到和输入相同尺寸的输出。
卷积核
注意下面的图,每个通道分别有各自的卷积核,使用的计算方法为点积,猜猜第二个图是怎么计算出来的呢?
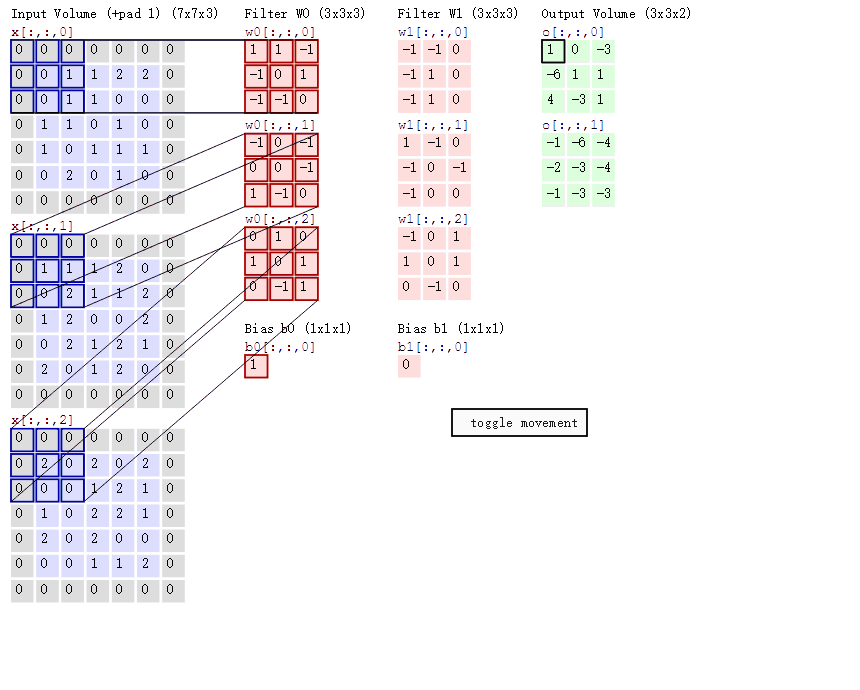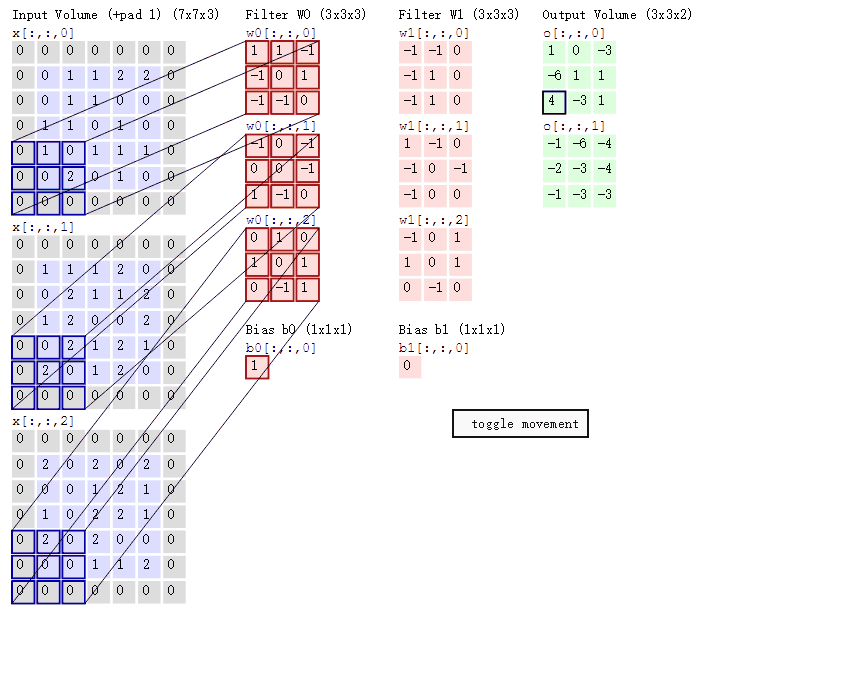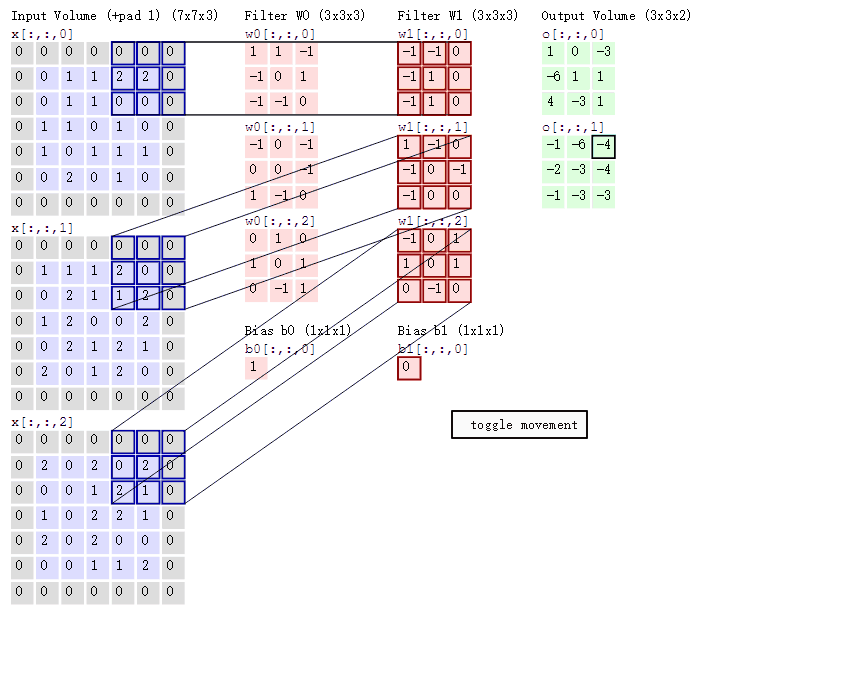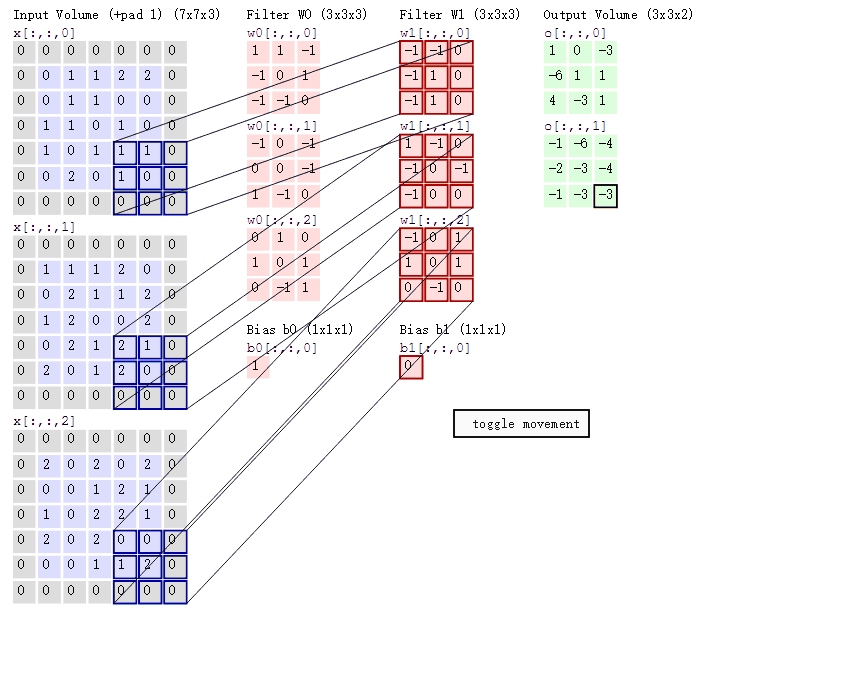
1 | #tf版本 |
池化
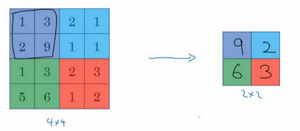
池化,也即降采样(subsample)。
上图为最大池化(max pool),输入是一个4×4矩阵,最大池化的pool_size为pool_size=(2, 2),步长为2,padding为“valid”,输出的每个元素都是其对应颜色区域中的最大元素值。除了最大池化,还有平均池化。
1 | #keras版本 |
经典卷积网络
- LeNet,这是最早用于数字识别的CNN
- AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比LeNet更深,用多层小卷积层叠加替换单大卷积层
- GoogLeNet, 2014 ILSVRC比赛冠军
- VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
- 残差网络,2015年的ImageNet上取得冠军
胶囊网络
写在前面
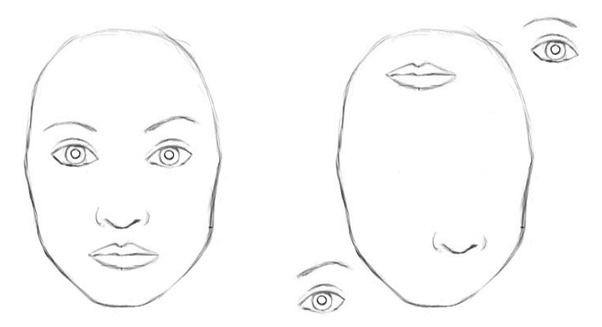
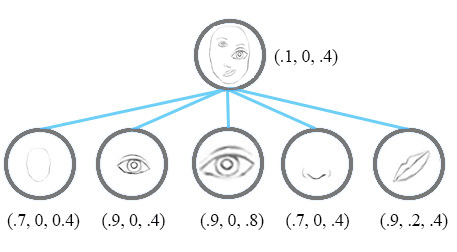
对于上面的两张图,CNN的结果显示,它们都是人脸!由此暴露了CNN的缺点:对物体之间的空间关系 (spatial relationship) 的识别能力不强。
Well to a network it has all the features of a face. When the convolution operations are applied they will be activated on all of those features!
An important thing to understand is that higher-level features combine lower-level features as a weighted sum: activation of a preceding layer are multiplied by the following layer neuron’s weights and added, before being passed to activation non-linearity. Nowhere in this information flow are the relationships between features taken into account.
Thus, we can say that the main failure of CNNs is that they do not carry any information about the relative relationships between features. This is simply a flaw in the core design of CNNs since they are based on the basic convolution operation applied to scalar values.
胶囊
胶囊含义
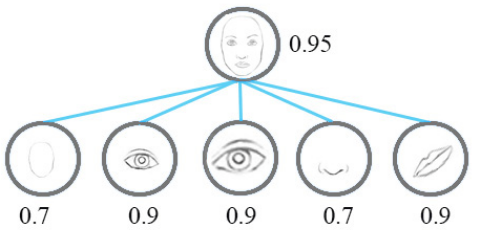
一个激活胶囊里的神经元的活动表示呈现在图像中的特定实体的各种属性。这些属性可以包括实例化参数的不同类型,如姿势(位置,大小,方向)、形变、速度、反射率、色调、纹理等等。下面的两个图分别是普通CNN和胶囊网络如何侦测面部特征的,可以看出,胶囊网络解决这个问题的方法是:使用向量 代替标量!
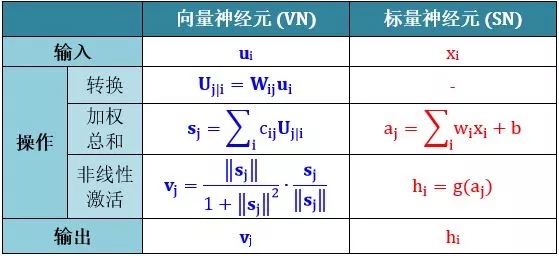
从下图可以对比传统的神经元和胶囊之间的区别:
工作原理
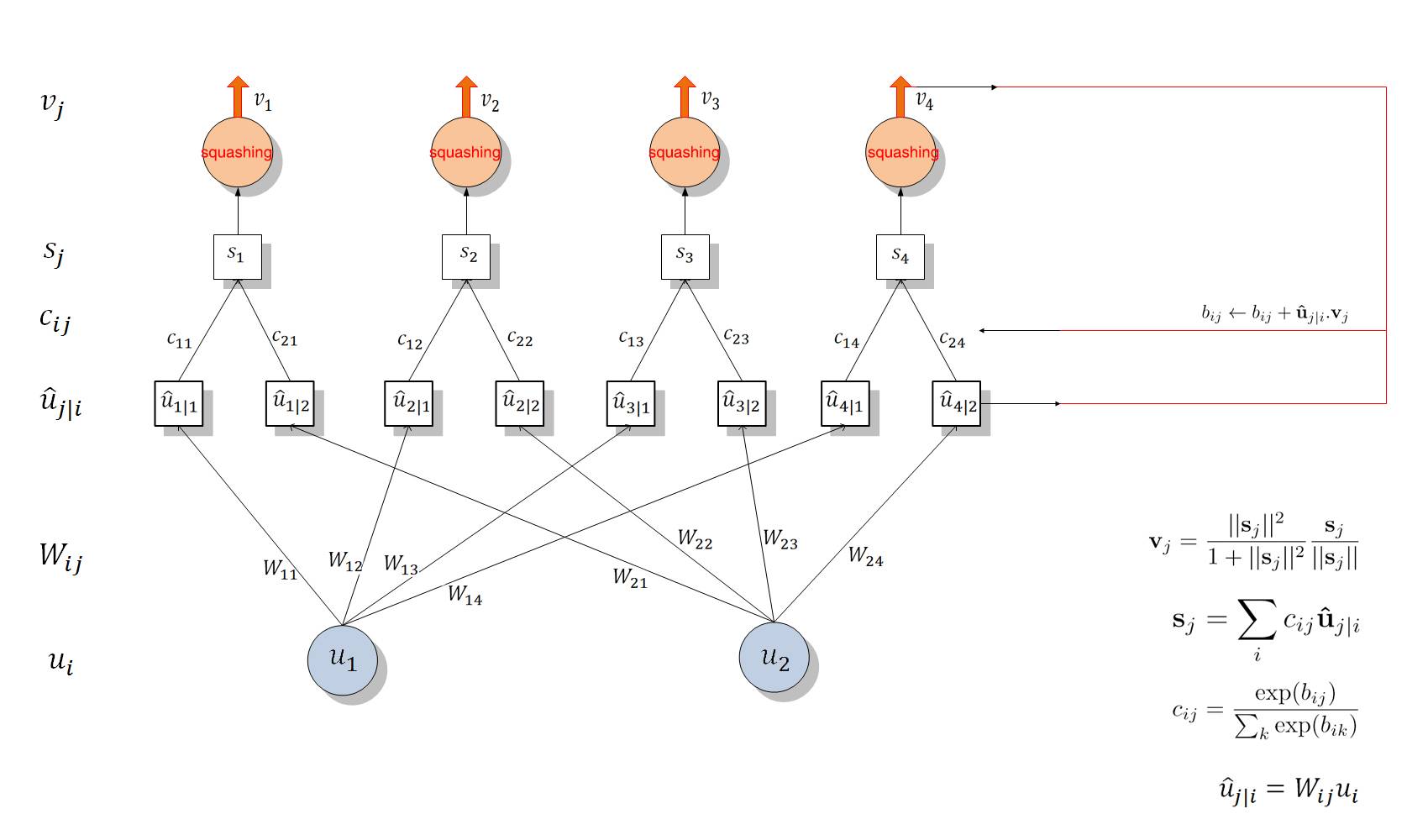
第一步是矩阵转化,即由输入$u_i$的低层特征转换为$\hat{u}_j|i$的高层特征。

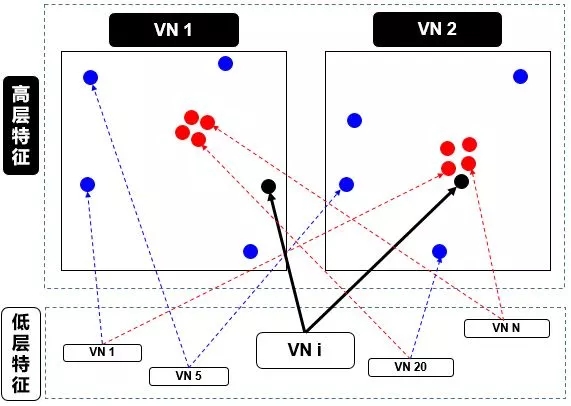
第二步是对高层特征,一个胶囊体的输出是一个向量,这使得它可以用一个强大的动态路由机制来确保胶囊的输出发送到上一层的父节点。最初,输出被路由输送到所有可能的父节点,但是被耦合系数缩减为总数为1。

我们用一个胶囊的输出向量的长度表示胶囊所代表的实体在当前的输入中存在的概率。因此,我们使用一个非线性的“挤压(squashing)”函数来确保短向量压缩到接近于0的长度,且长向量被压缩到略低于1的长度,我们让它进行识别学习来好好的利用这个非线性。
胶囊的模长代表这个特征的概率。
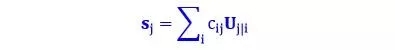

第三步,动态路由算法,伪代码如下:

为什么需要动态路由呢?因为计算$v_j$需要softmax($c_{ij}$),而在$c_{ij}$的更新中又需要$v_j$,所以这需要一个动态规划的思想,其实这个过程与聚类也有一点思想上的接近[6]。
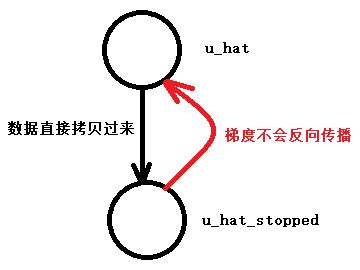
注意 在 SN 的情况下,这些权重是通过反向传播 (backward propagation) 确定的,但是在 VN 的情况下,这些权重是使用动态路由 (dynamic routing) 确定的,此时:
网络结构
第一个卷积层:输入:mnist:28x28、卷积核大小:9x9,卷积核个数:256,卷积核通道数:1,步长:1,输出:20x20x256
第二个卷积层(primarycaps):卷积核大小:9x9,卷积核通道数:32,卷积核个数:8,步长:2,输出:6x6x8x32
其中,连续两个卷积层采用动态路由替换池化操作。
动态路由(Digitscaps):输入:6x6x1x32(每个向量长度为8),即第 i 层共有 1152 个 Capsule 单元。而第三层 j 有 10 个标准的 Capsule 单元,每个 Capsule 的输出向量有 16 个元素。前一层的 Capsule 单元数是 1152 个,那么 $w_{ij}$ 将有 1152×10 个,且每一个 $w_{ij}$ 的维度为 8×16。
当$u_i$ 与对应的 $w_{ij}$ 相乘得到预测向量后,我们会有 1152×10 个耦合系数 $c_{ij}$,对应加权求和后会得到 10 个 16×1 的输入向量。将该输入向量输入到「squashing」非线性函数中求得最终的输出向量 $v_j$,其中 $v_j$ 的长度就表示识别为某个类别的概率。
损失函数
其中 c 是分类类别,$T_c$ 为分类的指示函数(c 存在为 1,c 不存在为 0),$m^+$ 为上边界(0.9),$m^-$ 为下边界(0.1)。此外,$v_c$ 的模即向量的 L2 距离。
我们在训练期间,除了特定的 Capsule 输出向量,我们需要蒙住其它所有的输出向量。然后,使用该输出向量重构手写数字图像。DigitCaps 层的输出向量被馈送至包含 3 个全连接层的解码器中,并以上图所示的方式构建。这一过程的损失函数通过计算 FC Sigmoid 层的输出像素点与原始图像像素点间的欧几里德距离而构建。Hinton 等人还按 0.0005 的比例缩小重构损失,以使它不会主导训练过程中的 Margin loss。
代码
代码查看:https://github.com/naturomics/CapsNet-Tensorflow
https://github.com/bojone/Capsule/blob/master/capsule_test.py
参考文献:
[1]. 先读懂CapsNet架构然后用TensorFlow实现,这应该是最详细的教程了
[2]. 胶囊(向量神经)网络
[3]. Dynamic Routing Between Capsules
[4]. CapsNet comparative performance evaluation for image
classification
[5]. Investigating Capsule Networks with Dynamic Routing for
Text Classification