背景
Attention model虽然解决了输入句仅有一个context vector的缺点,但依旧存在不少问题。
- context vector计算的是输入句、目标句间的关联,却忽略了输入句中文字间的关联,和目标句中文字间的关联性。
- 不管是Seq2seq或是Attention model,其中使用的都是RNN,RNN的缺点就是无法平行化处理,导致模型训练的时间很长。
Self attention是Google在Attention is all you need论文中提出的The transformer模型中主要的概念之一。Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。
Transformer在计算attention的方式有三种:
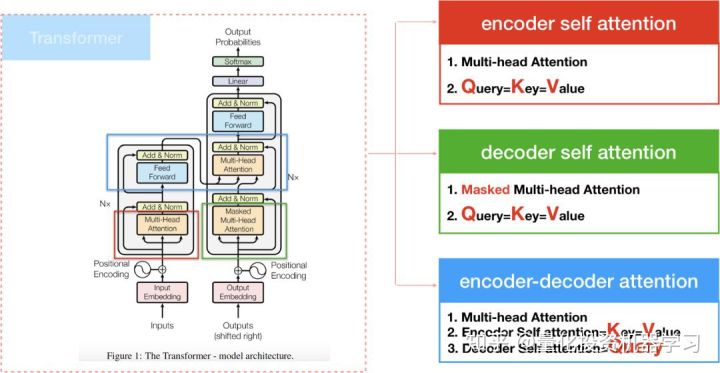
- encoder self attention,存在于encoder间
- decoder self attention,存在于decoder间
- encoder-decoder attention, 这种attention算法和过去的attention model相似
Encoder
Encoder的基本结构如下:
![]()
Encoder部分是由6个如图所示的encoder堆积而成的,其中的6并不是什么神奇的数字,你也可以更换成其他的。同样,Decoder部分是由6个的decoder堆积而成的。
![]()
Encoder Self Attention
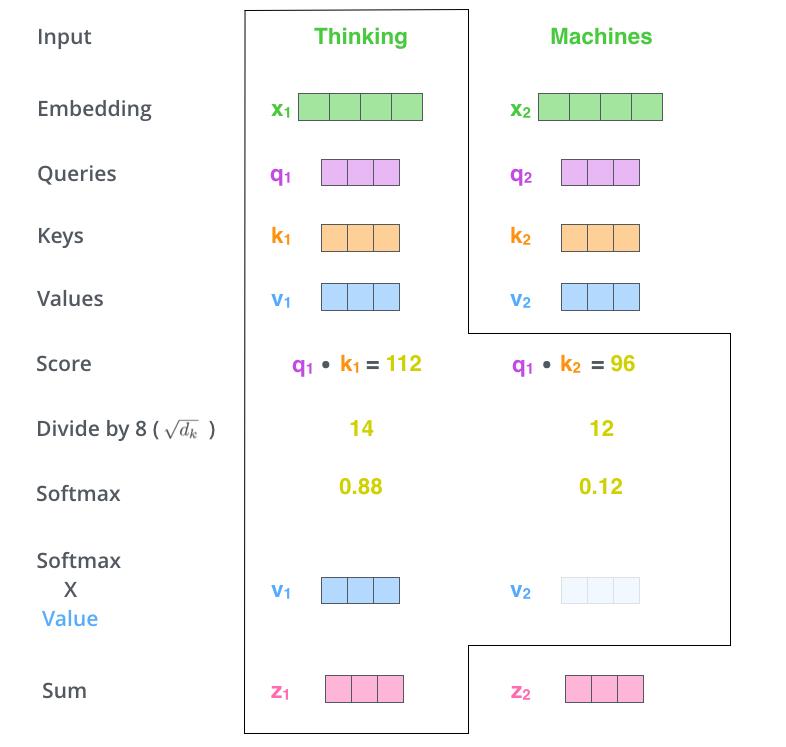
之前在Attention注意力机制提到,$K = V$ 时,键值对模式就等价于普通的注意力机制,此时K=V=word embedding vector。而在self attention中,Q=K=V=word embedding vector,即每个序列中的单词和该序列中所有单词进行attention计算。
计算流程
- 对word embedding vector(即图片中的X,$d_{model}$=512),接著我们会乘上一个初始化矩阵(512x64),得到$QKV$($d_k=f_q=d_v=64$)
- 计算score,即q·k
- score归一化,除以$\sqrt{d_k}$
- softmax计算
- 点乘Value值$v$ ,得到加权的每个输入向量的评分$v$
- 相加之后得到最终的输出结果:$\sum v$
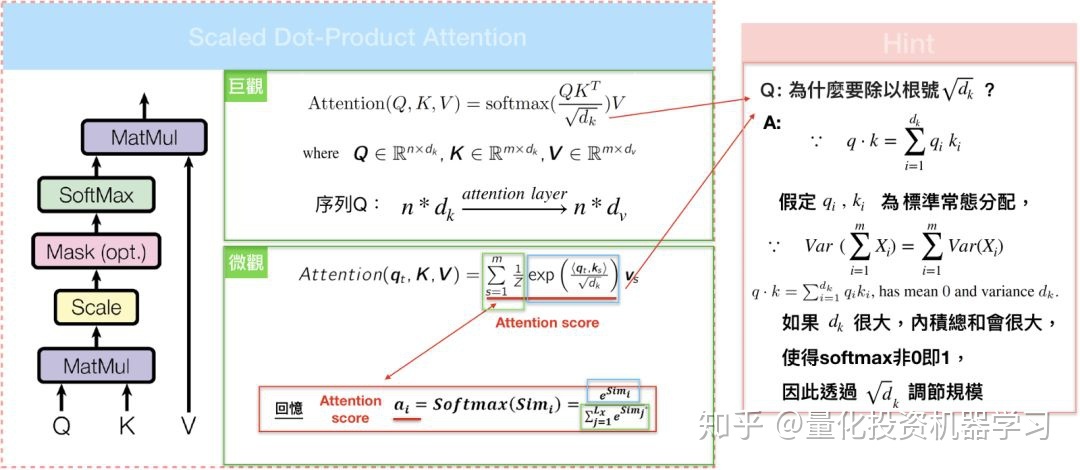
Scaled Dot-Product Attention
Self Attention采用了内积(缩放点积)运算,如图所示:
自注意力优点
每一层的复杂度:如果输入序列n小于表示维度d的话,每一层的时间复杂度Self-Attention是比较有优势的。
当n比较大时,作者也给出了一种解决方案Self-Attention(restricted)即每个词不是和所有词计算Attention,而是只与限制的r个词去计算Attention。是否可以并行: multi-head Attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于 RNN。长距离依赖: 由于Self-Attention是每个词和所有词都要计算Attention,所以不管他们中间有多长距离,最大的路径长度也都只是 1。可以捕获长距离依赖关系。
Multi-head attention
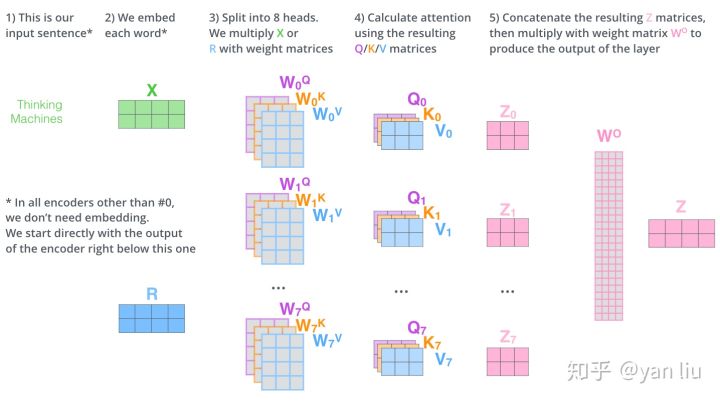
为了捕捉输入句中所有空间的讯息,把key、value,、query们线性投射到不同空间h次,h=8,对h个不同的self-attention的集成。
- 将word embedding vector(X)分别输入到图中所示的8个self-attention中,得到8个加权后的特征矩阵$z_i,i∈\{1,2,…,8\}$。
- 将8个$Z_i$按列拼成一个大的特征矩阵;
- 特征矩阵经过一层全连接后(图中的$W_O$)得到输出$z$
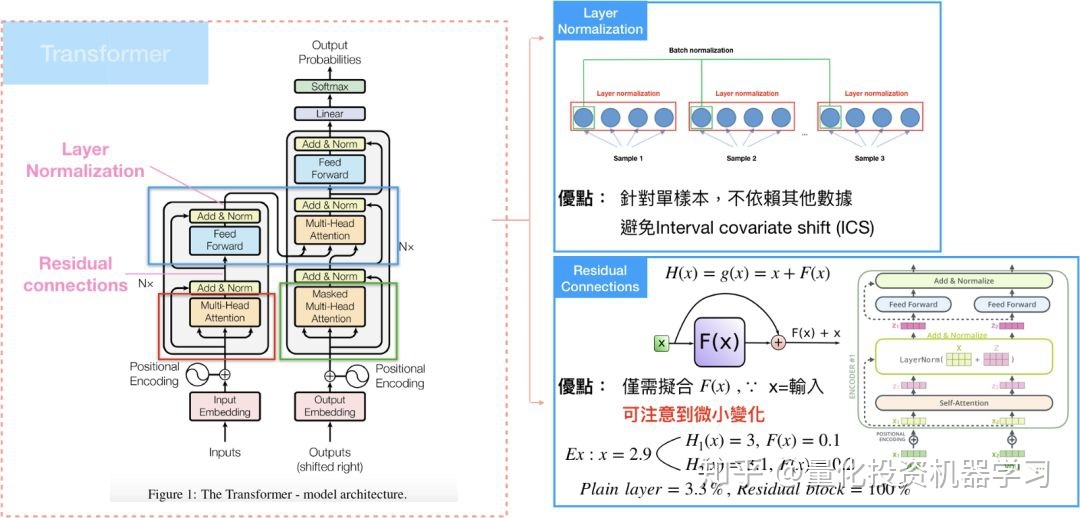
Residual Connection & Layer Normalization
Multihead-attention完再接到feed-forward layer之前,还有一个sub-layer,需要经过residual connection和layer normalization。
Residual connection 就是构建一种新的残差结构,将输出改写成和输入的残差,使得模型在训练时,微小的变化可以被注意到,这种架构很常用在电脑视觉(computer vision)。
Layer normalization是在深度学习领域中的一种正规化方法,计算可以参考:网络优化
Feed-Forward Networks
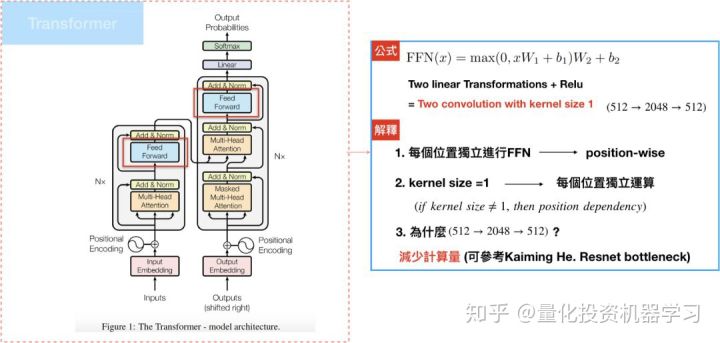
Encoder/Decoder中的attention sublayers都会接到一层feed-forward networks(FFN):两层线性转换和一个RELU,论文中是根据各个位置(输入句中的每个文字)分别做FFN。
其中,每个位置进行相同的线性转换,这边使用的是convolution1D(TF官网的是dense layer),也就是kernel size=1,原因是convolution1D才能保持位置的完整性,可参考CNN,模型的输入/输出维度$d_{model}=512$,但中间层的维度是2048,目的是为了减少计算量。
Positional Encoding
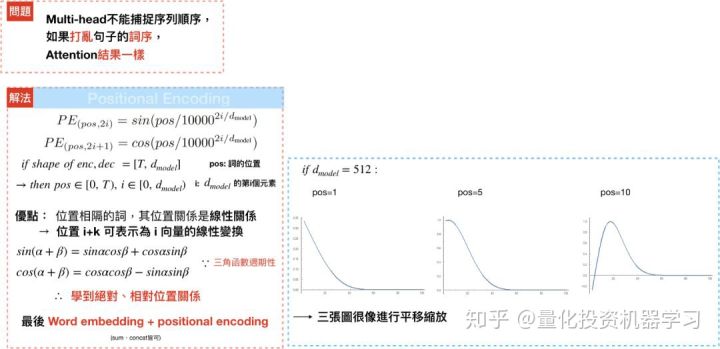
和RNN不同的是,multi-head attention不能学到输入句中每个文字的位置(这里暗示说了RNN可以学习相对位置)。举例来说,“Are you very big?” and “Are big very you?”,对multi-head而言,是一样的语句。因此,Transformer透过positional encoding,来学习每个文字的相对/绝对位置,最后再和输入句中文字的隐向量相加。
论文使用了方程式:
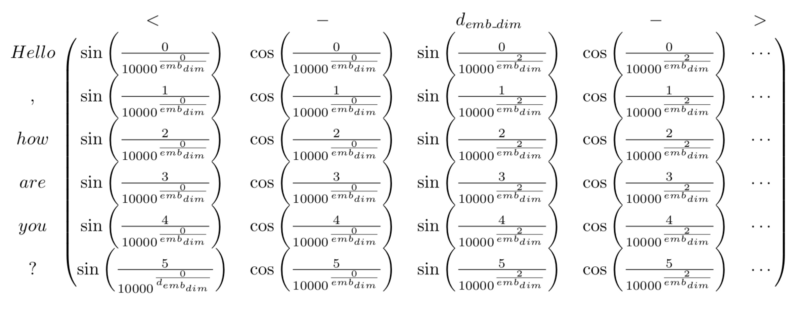
pos代表的是位置,i代表的是维度,偶数位置的文字会透过sin函数进行转换,奇数位置的文字则透过cos函数进行转换,借由三角函数,可以发现positional encoding 是个有周期性的波长;举例来说,[pos+k]可以写成PE[pos]的线性转换,使得模型可以学到不同位置文字间的相对位置。
The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention.
![]()
Decoder
Decoder的基本结构如图右下部分:
![]()
Masked multi-head attention
Decoder self attention与Encoder self attention基本结构一样,Decoder 的输入来自encoder outputs($d_{model}=512 $) 和decoder positon encoding(预测的时候来自上一时刻的预测值)。
不同的地方是:为了避免在解码的时后,还在翻译前半段时,就突然翻译到后半段的句子,会在计算self-attention时的softmax前先mask掉未来的位置(设定成-∞)。这个步骤确保在预测位置i的时候只能根据i之前位置的输出,其实这个是因应Encoder-Decoder attention 的特性而做的配套措施,因为Encoder-Decoder attention可以看到encoder的整个句子。
Encoder-Decoder Attention
Encoder-Decoder attention就类似于之前的s2s attention了,它的Query来自于decoder self-attention,而Key、Value则是encoder的output。
The Final Linear and Softmax Layer
Decoder最后会得出一个向量,传到最后一层linear layer后做softmax。Linear layer只是单纯的全连接层网络,并产生每个文字对应的分数,softmax layer会将分数转成机率值,最高机率的值就是在这个时间顺序时所要产生的文字。
![]()
![]()
评价
优点
- multi-head attention来解决平行化和计算复杂度过高的问题
- 长期依赖关系也能透过self-attention中词语与词语比较时,长度只有1的方式来克服
缺点
- 在语言建模的设置中受到固定长度上下文(fixed-length context)的限制(Transformer-XL)
- 对于长输入的任务,典型的比如篇章级别的任务(例如文本摘要),因为任务的输入太长,Transformer 会有巨大的计算复杂度,导致速度会急剧变慢
代码
代码参考:tensorflow官方版
其他
bert
BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能处理其左侧的上下文。双向 Transformer 通常被称为“Transformer encoder”,而左侧上下文被称为“Transformer decoder”,decoder是不能获要预测的信息的。
beam_search
teach_forcing
参考文献:
[1]. 自然语言处理中的自注意力机制
[2]. 从Seq2seq到Attention模型到Self Attention(二)
[3]. The Illustrated Transformer
[4]. 详解Transformer