为什么需要注意力机制
一般对于输入输出的不同部分具有不同的重要程度。例如,在翻译任务中,输出的第一个单词是一般是基于输入的前几个词,输出的最后几个词可能基于输入的几个词。例如在阅读理解任务中,编码时还不知道可能会接收到什么样的问句。这些问句可能会涉及到背景文章的所有信息点,因此丢失任何信息都可能导致无法正确回答问题。
注意力一般分为两种:一种是自上而下的有意识的注意力,称为聚焦式(focus)注意力。聚焦式注意力是指有预定目的、依赖任务的、主动有意识地聚焦于某一对象的注意力;另一种是自下而上的无意识的注意力,称为基于显著性(saliency-based)的注意力。基于显著性的注意力是由外界刺激驱动的注意,不需要主动干预,也和任务无关。
在目前的神经网络注意力机制也可称为注意力络模型中,我们可以将max pooling、gating机制来近似地看作是自下而上的基于显著性的注意力机制。除此之外,自上而下的会聚式注意力也是一种有效的信息选择方式。
普通注意力机制
结构
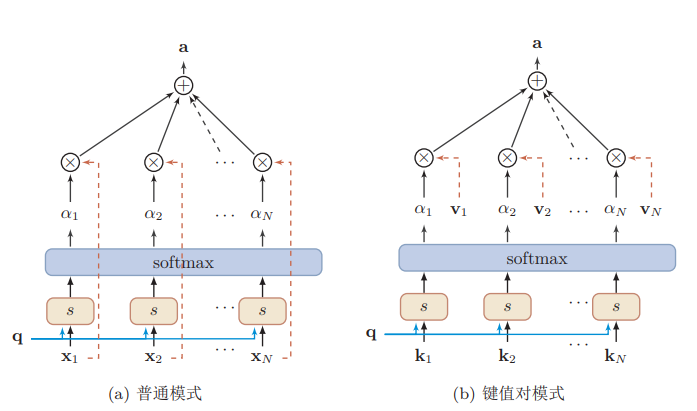
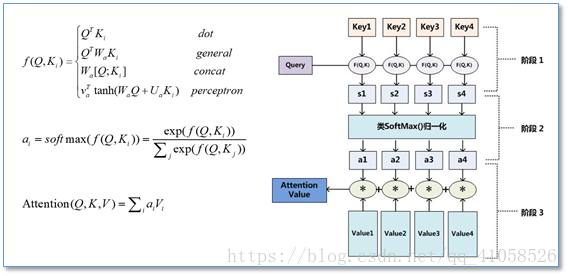
用$X = [x_1,…, x_N ]$表示$N$个输入信息,为了节省计算资源,不需要将所有的$N$个输入信息都输入到神经网络进行计算,只需要从$X$中选择一些和任务相关的信息输入给神经网络。给定一个和任务相关的查询向量$q$,我们用注意力变量$z ∈ [1, N]$来表示被选择信息的索引位置,即$z = i$表示选择了第$i$个输入信息。为了方便计算,我们采用一种软性的信息选择机制,首先计算在给定$q$ 和$X$ 下,选择第$i$个输入信息的概率$α_i$:
其中$α_i$ 称为注意力分布(attention distribution),$s(x_i, q)$为注意力打分函数,可以使用以下几种方式来计算:
其中$W, U, v$为可学习的网络参数,$d$为输入信息的维度。理论上,加性模型和点积模型的复杂度差不多,但是点积模型在实现上可以更好地利用矩阵乘积,从而计算效率更高。但当输入信息的维度d比较高,点积模型的值通常有比较大方差,从而导致softmax函数的梯度会比较小。因此,缩放点积模型可以较好地解决这个问题。相比点积模型,双线性模型在计算相似度时引入了非对称性。
注意力分布$α_i$可以解释为在上下文查询$q$时,第$i$个信息受关注的程度。我们采用一种软性的信息选择机制对输入信息进行编码为:
代码
1 | #keras版本 |
S2S注意力机制
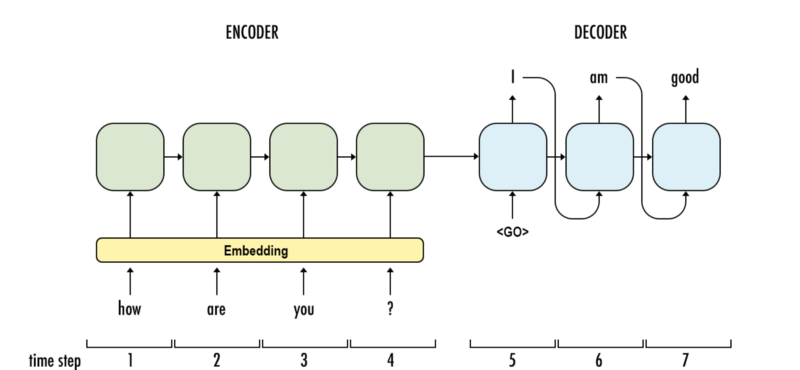
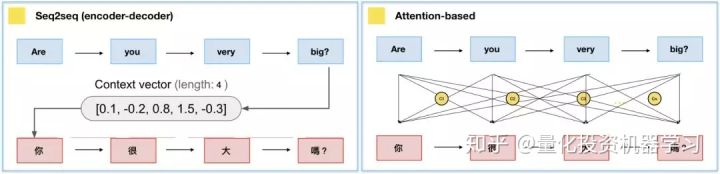
Seq2seq包含Encoder和Decoder,将句子输入至Encoder,即可从Decoder获得目标句。Encoder就是个单纯的RNN/LSTM/GRU(一般为双向结构),而Decoder比Encoder多了一个context vector,也就是Encoder当中,最后一个hidden state。然而,对于长句子的翻译,将输入句压缩成固定长度的context vector,当然效果不好。这个时候就需要注意力机制了。
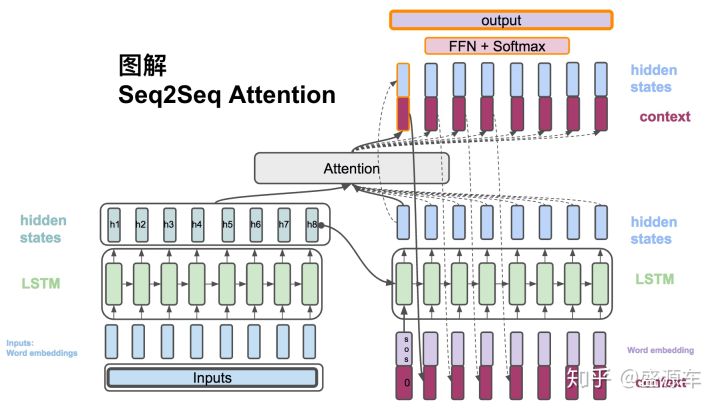
(1) $h_t = RNN_{enc}(x_t,h_{t-1})$,Encoder方面接受的是每一个单词word embedding,和上一个时间点的hidden state。输出的是这个时间点的hidden state。[6]
(2) $s_t= RNN_{dec}(\hat{y_{t-1}},s_{t-1})$ , Decoder方面接受的是目标句子里单词的word embedding,和上一个时间点的hidden state。
(3) $c_i =\sum_{k=1}^{T_{x}} a_{ij}h_j$, context vector是一个对于encoder输出的hidden states的一个加权平均。
(4) $a_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_{x}}exp(e_{ik})}$,每一个encoder的hidden states对应的权重。
(5) $e_{ij} = score(s_i,h_j)$,通过decoder的hidden states加上encoder的hidden states来计算一个分数,用于计算权重(4)。
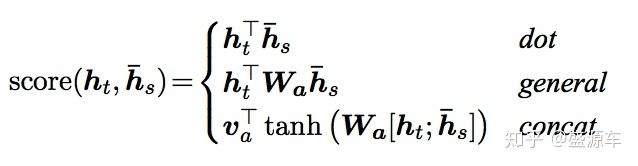
(6) $\hat{s_t} = tanh(W_c[c_t;s_t])$,将context vector 和 decoder的hidden states 串起来。
(7) $p(y_t|y_{<t},x)=softmax(W_s \hat{s_t})$,计算最后的输出概率。
(6):being the transformation function that outputs a vocabulary-sized vector
与普通注意力机制相比的话,后者的$x_i$即前者的Encoder输出$h_j$,后者的$q$即前者的Decoder输出$s_i$。
注意力机制变体
Hard attention 与 Soft attention
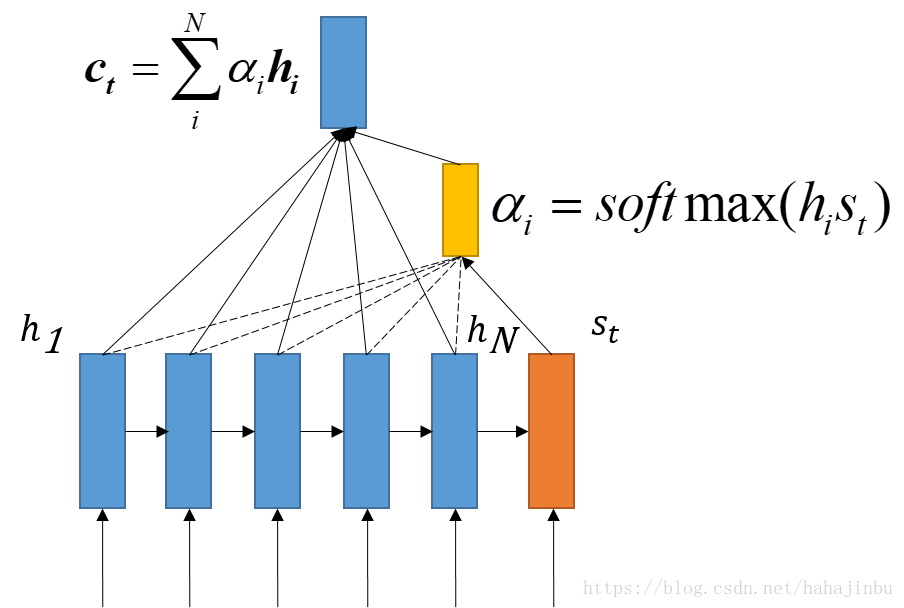
soft attention
普通注意力其实是软性注意力,其选择的信息是所有输入信息在注意力分布下的期望。
Hard attention
只关注到某一个位置上的信息,叫做硬性注意力。
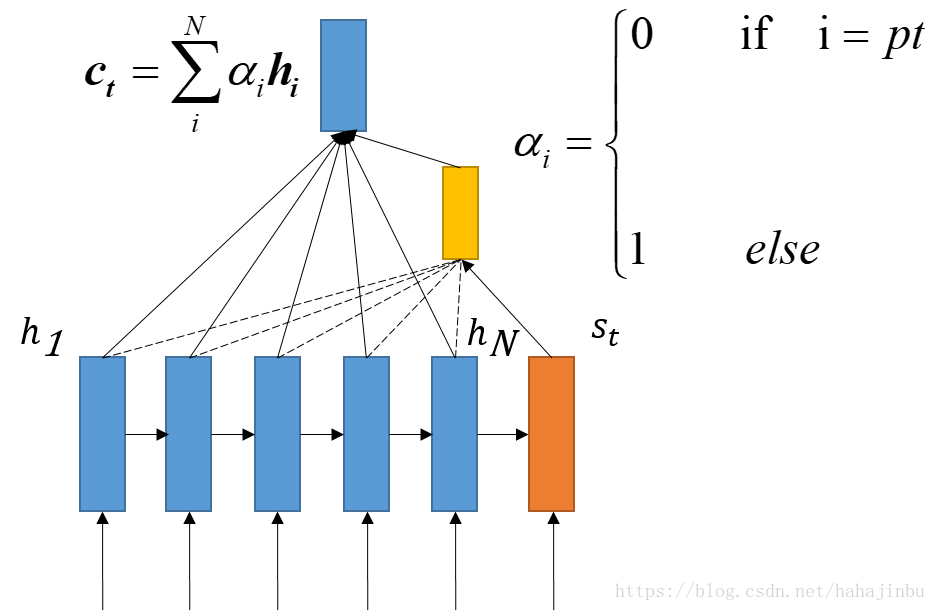
键值对Attention Model
键用来计算注意力分布$α_i$,值用来计算聚合信息。
输入句中的每个文字是由一系列成对的 <地址Key, 元素Value>所构成,而目标中的每个文字是Query,那么就可以用Key, Value, Query去重新解释如何计算context vector,透过计算Query和各个Key的相似性,得到每个Key对应Value的权重系数,权重系数代表讯息的重要性,亦即attention score;Value则是对应的讯息,再对Value进行加权求和,得到最终的Attention/context vector。
用$(K, V ) = [(k_1, v_1), …,(k_N , v_N )]$表示$N$个输入信息,给定任务相关的查询向量$q$时,注意力函数为:
$s(k_i, q)$为打分函数。当$K = V$ 时,键值对模式就等价于普通的注意力机制。注意有些写法把QK的位置互换:
多头注意力
是利用多个查询$Q = [q_1, … , q_M]$,来平行地计算从输入信息中选取多个信息。每个注意力关注输入信息的不同部分。
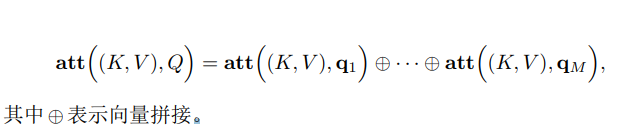
缺点
Attention model虽然解决了输入句仅有一个context vector的缺点,但依旧存在不少问题。
context vector计算的是输入句、目标句间的关联,却忽略了输入句中文字间的关联,和目标句中文字间的关联性。
不管是Seq2seq或是Attention model,其中使用的都是RNN,RNN的缺点就是无法平行化处理,导致模型训练的时间很长。
参考文献:
[1]. 注意力机制与外部记忆
[2]. 从Seq2seq到Attention模型到Self Attention
[4]. tf.contrib.seq2seq.BahdanauAttention
[5]. tf.contrib.seq2seq.LuongAttention
[6]. 图解seq2seq attention